Spark에서 groupByKey 대신 reduceByKey 사용하기
이번 포스트에서는 스파크에서 빈번히 사용되는 transformation인 reduceByKey와 groupByKey의 동작에 대해 살펴보겠습니다.
먼저 스파크에서 reduceByKey와 groupByKey를 사용하여 단어 세기 예제를 작성해보도록 하겠습니다.
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()
두 방법 모두 정확한 답을 출력합니다. 그러나 reduceByKey가 큰 데이터 셋에서는 더 효율적으로 동작합니다. 그 이유는 reduceByKey의 내부적인 동작의 차이 때문입니다. reduceByKey는 키를 기준으로 셔플링을 하기 전에 미리 각 파티션 내에 있는 데이터들을 먼저 combine을 수행합니다. 맵리듀스의 combiner를 사용하는 것과 동일한 역학을 수행하는 것입니다.
아래의 그림을 보면 reduceByKey가 어떻게 동작하는지 더 손쉽게 이해할 수 있습니다.
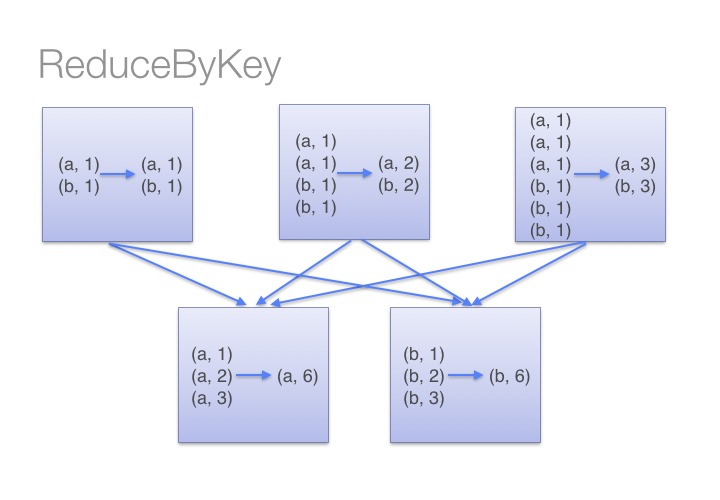
반면에 groupByKey는 모든 키-값 페어에 대해 셔플을 수행합니다. 이러한 동작은 단어 세기 예제와 같은 경우 불필요한 셔플을 발생하여 네트워크 자원을 더 많이 소모하게 됩니다.
스파크는 하나의 executor가 가진 메모리보다 더 많은 셔플 데이터를 처리해야 하는 경우에는 데이터를 디스크로 저장하게 됩니다. 만일 하나의 키가 가진 키-값 데이터가 executor의 메모리를 넘어가게 되는 경우에는 out of memory 예외가 발생하게 됩니다. 이러한 상황이 발생하지 않도록 애플리케이션을 작성해야 합니다.
groupByKey의 동작은 아래의 그림과 같습니다.
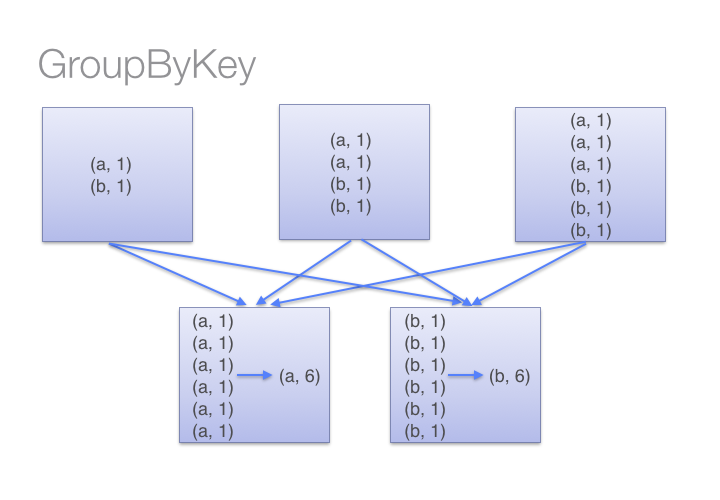
훨씬 큰 데이터 셋에서 reduceByKey와 groupByKey는 셔플링하는 데이터 차이가 극명합니다. groupByKey 대신 사용할 수 있는 다른 함수들도 존재합니다.
combineByKey는 키를 가진 값들을 하나로 병합하는 기능을 수행하지만 병합을 수행하는 과정에서 값의 타입이 바뀔 수 있습니다.foldByKey는reduceByKey와 다르게 초기값인zeroValue를 전달해서 병합 시 사용할 수 있습니다.