배치 프로세싱(Batch processing) - 1
배치 처리는 컴퓨터 연산의 오래된 형태 중에 하나입니다. 이미 배치 처리는 예전 부터 사용했습니다. 2004년에 발표된 구글의 맵리듀스는 과거 미국 인구 조사에서 천공 카드 집계기를 이용한 집계 처리와 유사합니다. 이와 같이 배치 처리는 입력 데이터로 집계 처리해서 결과를 보여줍니다. 이와 같은 것들은 유닉스의 설계 철학을 통해 다시 한번 살펴볼 수 있습니다. 유닉스 설계 철학이 최근 데이터 프레임워크에 어떻게 반영되었는지 살펴보기 위해 간단히 유닉스 툴들로 배치 처리하는 방법을 간단히 살펴보겠습니다.
유닉스 툴로 배치 처리하기
유닉스 툴로 nginx의 엑세스 로그를 분석하는 예를 살펴보겠습니다. nginx의 로그의 예는 다음과 같습니다.
216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1" 200 3377 "http://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36"
로그가 의미하는 바는 다음과 같습니다.
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"
로그에 대한 자세한 설명은 생략하도록 하겠습니다.
이제 엑세스 로그를 활용해서 웹사이트 트래픽에 관한 보고서를 만들 수 있습니다. 유닉스 툴을 이용하여 웹사이트에서 가장 인기 높은 페이지 5개를 뽑는 방법은 다음과 같습니다. 유닉스의 설계 철학은 위키피디아에서 확인할 수 있습니다.
cat /var/log/nginx/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -r -n |
head -n 5
- 로그를 읽습니다.
- 한 줄마다 공백으로 나누어 7번째 필드만 출력합니다. 위 예제에서는
/css/typography.css가 되겠습니다. - 요청 url을 알파벳 순서로 정렬합니다. 동일한 url이 n번 요청되면 url은 연속으로 n번 반복되서 출력됩니다.
- uniq 명령은 인접한 두 줄이 같은지 확인해서 중복을 제거합니다. -c 옵션은 중복 횟수를 출력하는 옵션입니다. 즉 url이 몇 번 요청되었는지 세는 역할을 수행합니다.
- 정렬을 하는데 -r 옵션은 내림차순 정렬이고, -n 옵션은 한 줄에 처음 나오는 숫자를 기준으로 정렬하라는 옵션입니다.
- 마지막으로 head 명령어는 앞에서 5줄만을 출력하라는 의미입니다.
위와 같은 유닉스 툴을 이용하면 수 기가바이트의 로그 파일을 수 초내로 처리가 가능합니다. 이와 같이 명령의 조합을 통해 쉽게 로그 파일을 분석할 수 이유는 유닉스 설계 철학에 있습니다. 유닉스 설계 철학은 아래와 같습니다.
- 각 프로그램이 한 가지 일만 하도록 만들어라. 새로운 작업을 위해 기존 프로그램을 수정하여 기능을 추가해 프로그램을 복잡하게 만들기 보다는 새 프로그램을 만들어라.
- 모든 프로그램의 출력은 아직 알려지지 않은 다른 프로그램의 입력으로 쓰일 수 있다는 것을 예상하라. 불필요한 정보로 출력을 어지르지 마라. 엄격한 컬럼 형식이나 이진 입력 포맷의 사용을 피하라. 대화형 입력을 고집하지 마라.
- 소프트웨어를 빠르게 써볼 수 있도록 설계하고 구축하라. 심지어 운영체제도 마찬가지다. 수 주이내에 마치는 것이 이상적이다. 거슬리는 부분을 과감히 버리고 다시 구축하는 것을 주저하지 마라.
- 프로그래밍 작업을 줄일려면 미숙한 도움보다는 툴을 사용하라. 도구를 빌드하기 위해 우회해야 하고 사용 후 바로 버려야할 지라도 말이다.
위의 유닉스 설계 철학에는 자동화, 빠른 프로토타이핑, 증분 반복, 실험 친화, 큰 프로젝트를 처리가능한 청크 단위로 처리하기와 같은 방법을 살펴볼 수 있습니다. 이것은 오늘날 애자일과 데브옵스(DevOps)와 같은 방식과 굉장히 유사합니다. 이러한 유닉스 툴을 이용하면 작은 여러 프로그램으로 강력한 데이터 처리 작업을 쉽게 구성할 수 있습니다. 이것은 프로그램 사이에 동일한 인터페이스를 사용하도록 했기 때문입니다. 유닉스에서의 인터페이스는 파일(좀 더 정확히는 파일 디스크립터)입니다. 파일은 단지 순서대로 정렬된 바이트의 연속입니다. 그래서 위의 로그 분석 예제에서는 파일로부터 연속된 바이트를 아스키 텍스트로 취급하여 동일하게 처리하였습니다.
맵리듀스와 분산 파일 시스템
하나의 맵리듀스 잡은 하나 이상의 입력을 받아 하나 이상의 출력을 만들어 낸다는 점에 하나의 유닉스 프로세스와 유사합니다. 그러나 맵리듀스는 수천 대의 장비로 분산해서 실행 가능한 것이 차이점입니다. 유닉스 툴들은 주로 stdin과 stdout을 입력과 출력으로 사용하지만 맵리듀스는 분산 파일 시스템의 파일에 입출력을 사용합니다. 하둡 맵리듀스의 경우 분산 파일 시스템을 HDFS(Hadoop Distributed File System)이라고 합니다.
맵리듀스 잡 실행
맵리듀스는 HDFS에 있는 대용량 데이터셋을 처리하는 코드를 작성하는 프로그래밍 프레임워크입니다. 앞서 설명한 예제인 로그 분석의 예제는 맵리듀스의 데이터 처리 패턴과 상당히 유사합니다. 웹 서버 로그 분석하는 예제를 맵리듀스로 처리하는 과정은 다음과 같습니다.
- 입력 파일을 읽고 레코드로 쪼갠다.
- 각 입력 레코드마다 매퍼 함수를 호출해 키와 값을 호출한다.
- 키를 기준으로 키-값 쌍을 모두 정렬한다.
- 정렬된 키-값 쌍을 대상으로 리듀스 함수를 호출한다.
맵리듀스 잡의 경우 4단계로 수행이되는데 2단계(맵)와 4단계(리듀스)는 사용자가 직접 데이터 처리를 어떻게 할 것인지 지정하며, 1단계는 파일을 나누어 레코드를 만드는 인풋 포맷을 사용하고 3단계는 정렬 단계 인데 셔플 단계라고도 하고 맵리듀스 프레임워크에서 처리하는 단계입니다.
맵리듀스의 분산 실행
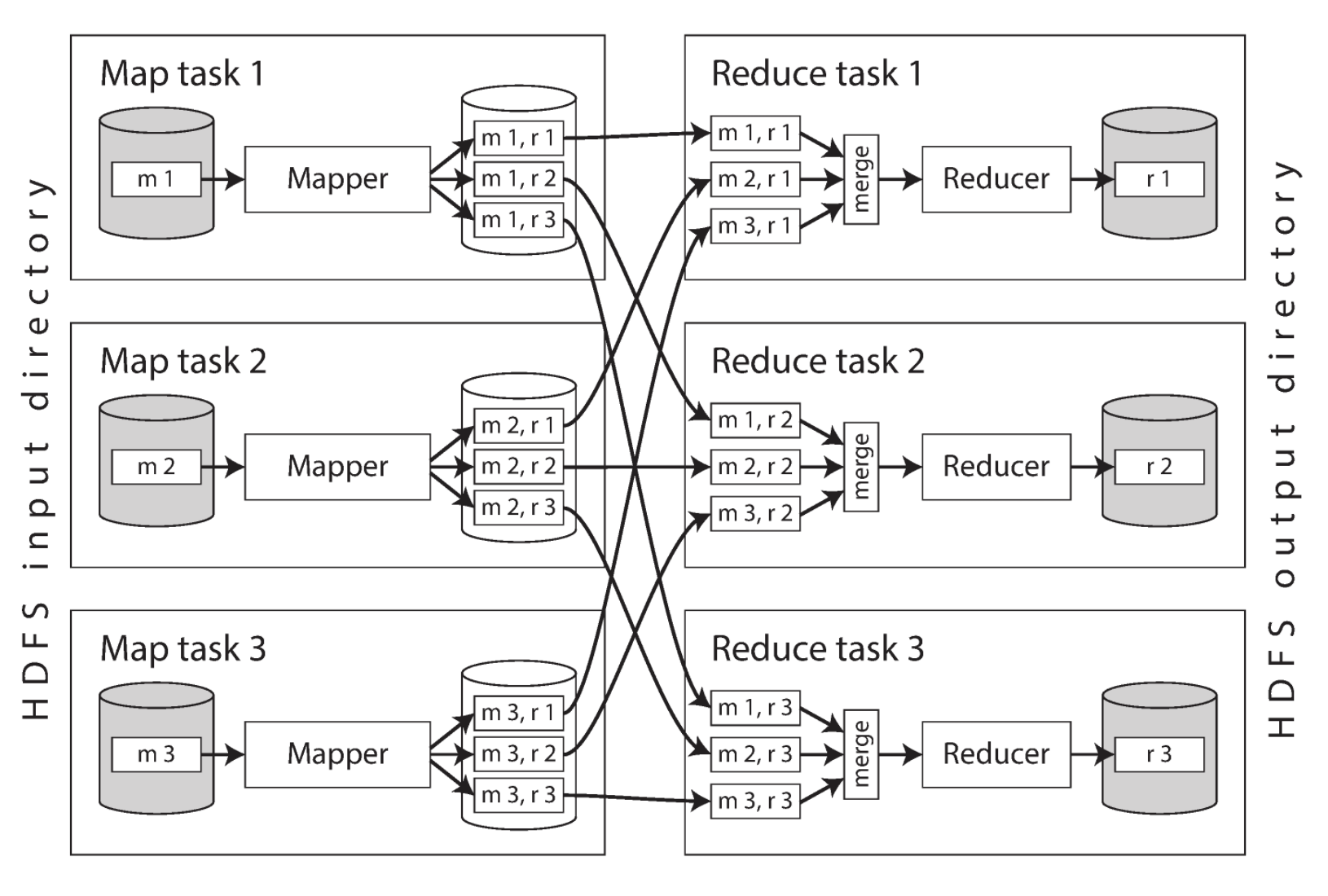
위 그림은 하둡 맵리듀스 잡에서 데이터 처리가 어떻게 이루어지는지 보여줍니다. 맵리듀스 잡은 파티셔닝 기반의 분산 처리를 수행합니다. 입력 데이터는 HDFS에 있는 데이터를 사용하는 것이 일반적입니다. 맵 태스크의 수는 입력 파일의 블록 개수로 결정되며 리듀스 태스크 수는 사용자가 설정할 수 있습니다.
맵리듀스에서는 같은 키를 가진 모든 키-값 쌍을 같은 리듀서에서 처리하는 것을 보장합니다. 키-값 쌍이 어느 리듀스 태스크에서 실행될 지 경정하기 위해 키의 해시값을 사용합니다. 그리고 리듀서에 전달되기 전에 키-값 쌍은 정렬되어 있어야 합니다. 주로 맵리듀스에서 처리되는 태스크의 경우 데이터가 매우 크기 때문에 단계를 나누어서 정렬을 수행합니다. 이와 같이 리듀서를 기준으로 파티셔닝을 하고 정렬한 뒤 매퍼로부터 데이터를 복사하는 과정을 셔플이라고 합니다. 그리고 처리된 출력 레코드는 HDFS에 기록됩니다.
맵리듀스 워크플로우
하나의 맵리듀스 잡으로 해결할 수 있는 문제는 한정적입니다. 그렇기 때문에 여러 맵리듀스 잡을 연결해서 워크플로우(workflow) 방식으로 구성해서 사용합니다. 이러한 워크플로우는 하나의 잡이 완료되어 나온 출력 디렉토리가 다음 맵리듀스의 입력 디렉토리로 설정하여 처리합니다. 이와 같이 맵리듀스 작업 간의 의존성 관리를 위해 다양한 스케줄러가 개발되었는데 대표적인 것들이 우지(Oozie), 아즈카반(Azkaban), 루이지(Luigi), 에어플로우(Airflow), 핀볼(Pinball) 등이 있습니다.
정리
이번 포스트에서는 배치 처리에 관해 살펴보았습니다. 유닉스 툴을 살펴보면서 이러한 도구들의 설계 철학이 어떻게 맵리듀스에 영향을 끼쳤는지 살펴보았습니다. 이 설계 원리의 대표적인 것을 살펴보면 먼저 입력은 불변이고 출력은 다른 프로그램의 입력으로 사용하는 것입니다. 그리고 복잡한 문제도 한가지 일을 잘하는 작은 툴을 엮어서 해결하는 것입니다. 유닉스 환경에서 프로그램과 다른 프로그램을 연결하는 단일 인터페이스는 파일과 파이프입니다. 맵리듀스의 인터페이스는 분산 파일 시스템입니다. 다음 포스트는 이어서 맵리듀스에서 사용되는 조인 알고리즘에 관해 살펴보고, 맵리듀스와 MPP 데이터베이스를 비교해서 살펴보고, 맵리듀스를 넘어 데이터 플로우 엔진에 관해 살펴보겠습니다.