데이터 모델(Data Models)과 질의 언어(Query Languages) - 1
데이터 모델은 소프트웨어 개발에 있어서 가장 중요한 부분 중에 하나입니다. 다양한 종류의 데이터 모델에 대해 이해를 하고 있고, 애플리케이션 요구사항에 가장 적합한 모델을 찾아서 개발을 해야 합니다.
데이터 모델에 따라 어떤 종류의 사용법은 쉽고 어떤 동작은 지원하지 않습니다. 또한 어떤 연산은 빠르지만 어떤 연산은 매우 느리게 동작할 수 있습니다. 그렇기 때문에 애플리케이션에 맞는 데이터 모델을 사용하는 것이 중요합니다.
이번 장에서는 다양한 데이터 모델과 질의 언어에 대해 살펴볼 예정입니다.
관계형 모델(Relational Model) vs 문서 모델(Document Model)
관계형 모델을 다음과 같이 정의됩니다. 데이터는 관계(relation)(SQL에서 테이블이라고 불리는)로 구성되고 각 관계는 순서 없는 튜플(tuple)(SQL에서 row라고 불리는) 모음입니다. 이러한 관계형 모델은 오늘날 웹에서 볼 수 있는 대부분의 서비스들이 사용하고 있습니다. 이러한 관계형 데이터베이스의 우위는 약 25-30년 정도 지속되었습니다. 관계형 모델의 예를 그림으로 살펴보도록 하겠습니다. 아래의 그림은 관계형 스키마를 사용해 링크드인 프로필을 표현한 것입니다.
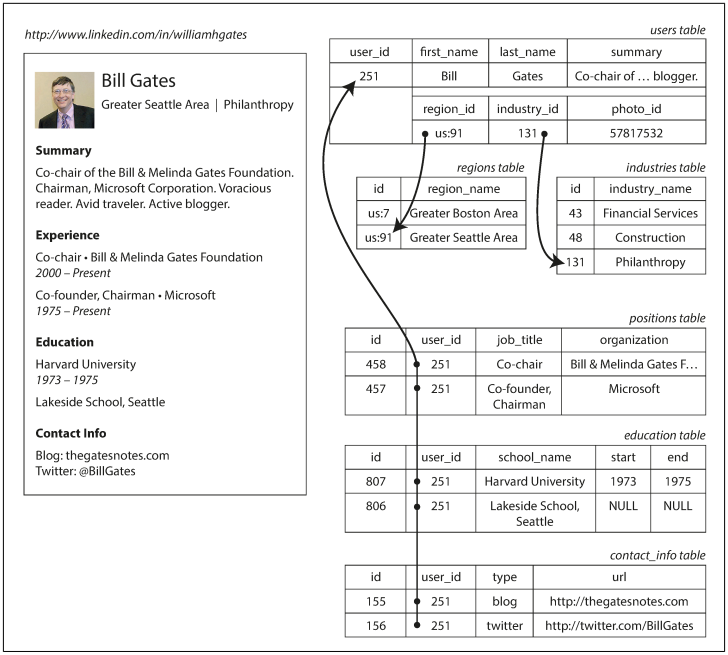
일대다(one-to-many) 관계
사용자와 직위, 학력, 연락처 정보는 일대다(one-to-many) 관계입니다. 이러한 관계를 표현하기 위해서 전통적인 SQL 모델에서 가장 일반적인 정규화 표현은 직위, 학력, 연락처 정보를 개별 테이블에 넣고 외래키로 users 테이블을 참조하는 방식을 사용합니다.
그러나 사실 이력서와 같은 데이터 구조는 모든 내용을 갖추고 있는 문서(document)이기 때문에 JSON으로 표현하는 것이 매우 적합합니다. 즉 아래와 같이 JSON으로 나타낼 수 있습니다.
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}
이와 같이 이력서를 문서데이터인 JSON으로 표현을 하면 관계형 모델에서 사용하는 다중 테이블 스키마보다 더 나은 locality를 갖는 장점이 있습니다. 즉, 관계형 예제에서와 같이 하나의 프로필을 가져오려면 다중 질의를 수행하고 다중 조인을 수행해야 합니다. 그러나 문서 모델은 모든 정보가 한 곳에 있기 때문에 하나의 질의로 충분합니다.
다대일(many-to-one) 관계
위에서 관계형 모델로 나타낸 이력서를 보게 되면 region_id와 industry_id는 일반 string 값이 아닌 id로 처리하였습니다. 사실 사용자에게 입력을 받을 수 있지만 지역을 나타내거나 업계의 표준 목록과 같은 것들은 드롭 다운이나 자동 완성 기능을 만들어 사용자가 선택하게 하는 게 더 좋습니다. 또한 id를 사용하는 경우 텍스트로 직접 저장하는 것에 비해 정보를 저장할 때 덜 중복되게 저장할 수 있는 장점이 있습니다. 사실 이러한 중복을 제거하는 일이 데이터베이스의 정규화의 핵심입니다.
중복된 데이터를 정규화 하려면 다대일(many-to-one) 관계가 필요합니다. 예를 들어 “많은 사람들은 한 특정 지역에 살고 있고, 많은 사람이 한 회사에서 일한다.“와 같은 관계를 말합니다. 이와 같은 다대일 관계는 문서 모델에 적합하지 않습니다. 관계형 DB에서는 조인이 쉽게 때문에 이와 같은 다대일 관계를 처리하고 용이합니다. 그러나 문서 데이터베이스는 일대다 관계를 처리하기 위해서 조인이 필요하지 않은 장점이 있지만 조인에 대한 지원이 약해서 다대일 관계를 처리하는데 어려움이 있습니다.
다대다(many-to-many) 관계
이번엔 다대다 관계입니다. 이력서에 대한 모델에 추가 요구 사항이 생겼다고 가정하겠습니다. 첫번째 요구사항은 organization(사용자가 일하는 회사)과 school_name(사용자가 공부한 학교)는 문자열이었습니다. 그러나 이것을 문자열 대신 entity로 참조하고 싶은 경우입니다. 이러한 요구사항을 반영한 예제는 아래의 그림과 같습니다.

추가적인 요구사항으로 사용자가 다른 사용자를 위해 추천서를 작성하는 기능을 넣는다고 가정해봅시다. 추천서는 추천받은 사용자의 이력서에 추천인의 이름과 사진이 함께 보입니다. 만약 추천인이 자신의 프로필 사진을 갱신하면 추천인이 작성한 모든 추천서에 새로운 사진을 반영해야 합니다.
이와 같이 두가지 요구사항과 같은 기능은 다대다(many-to-many) 관계를 나타냅니다. 이와 같은 다대다 관계는 아래의 그림으로 표현할 수 있습니다.
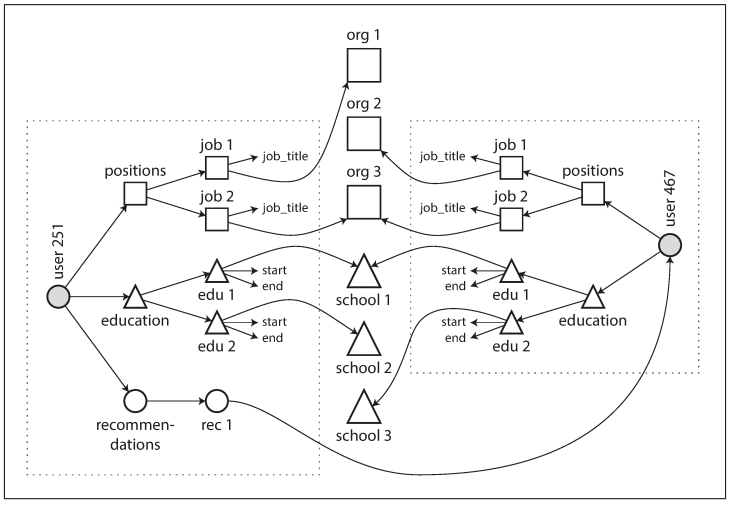
위 그림을 보면 점선 내의 데이터는 하나의 문서로 표현할 수 있지만, 회사, 학교, 추천인 사용자와 같은 것은 참조로 표현해야 하며 조인이 필요합니다.
관계형 데이터베이스와 문서 데이터베이스
관계형 데이터베이스와 문서 데이터베이스를 비교하는 경우는 내결함성과 동시성 처리를 포함해 고려해야 할 사항이 많지만 데이터 모델의 차이점에만 집중을 해봅시다.
문서 데이터 모델을 선호하는 이유는 스키마 유연성과 지역성에 기인한 더 나은 성능과 애플리케이션에 사용하는 데이터 구조가 더 가깝기 때문입니다. 관계형 모델은 조인, 다대일, 다대다 관계를 더 잘 지원하기 때문에 기존에 많은 애플리케이션들이 많이 사용했습니다.
위와 같이 애플리케이션에서 사용하는 데이터 구조가 문서와 비슷한 경우 문서 모델을 사용하는 것이 좋으며, 애플리케이션에서 다대다 관계를 사용하는 경우에는 문서 모델보다는 관계형 모델을 사용하는 것이 더 좋습니다.
상호 연결이 많은 데이터의 경우는 문서 모델은 좀 어려운 면이 있으며, 관계형 모델은 이러한 연결을 충분히 해결해 줍니다. 그러나 상호 연결이 많은 경우에는 그래프형 데이터 모델을 고려해볼 수 있습니다.
그래프형 데이터 모델
앞에서 다대다 관계가 다양한 데이터 모델을 구별할 수 있는 주요 관계임을 살펴보았습니다. 애플리케이션이 주로 일대다 관계(트리 구조 데이터)이거나 레코드 간 관계가 없다면 문서 모델이 적합합니다. 그러나 이와는 다르게 다대다 관계가 일반적으로 사용되는 애플리케이션이라면 어떻게 해야 할까요? 관계형 모델은 단순한 다대다 관계를 다룰 수 있지만, 데이터 간 연결이 복잡해지면 그래프로 데이터를 모델링하는 것이 더 편합니다.
그래프는 두 가지 객체로 구성됩니다. 하나는 정점(vertex)이고 다른 하나는 간선(edge) 입니다. 다양한 유형의 데이터를 그래프로 모델링할 수 있는데 일반적으로 다음과 같은 것들이 있습니다.
- 소셜 그래프
- 정점은 사람, 간선은 알고 있는 사람간의 관계
- 웹 그래프
- 정점은 웹페이지, 간선은 다른 페이지의 링크
- 도로나 철도 네트워크
- 정점은 교차로, 간선은 도로나 철로
위의 예제는 그래프의 정점이 모두 같은 유형을 나타내고 있습니다. 그러나 그래프는 이렇게 같은 유형뿐만 아니라 다른 유형의 데이터를 일관성 있게 저장할 수 있는 방법을 제공합니다. 예를 들어 페이스북에서는 정점이 사람, 장소, 이벤트, 체크인, 코멘트 등을 사용합니다. 그리고 간선은 어떤 사람이 서로 친구인지, 어떤 위치에서 체크인이 발생했는지, 누가 어떤 포스트에 코멘트를 했는지, 누가 이벤트에 참석했는지를 나타냅니다. 다음 그림은 그래프 구조 데이터 예제입니다.
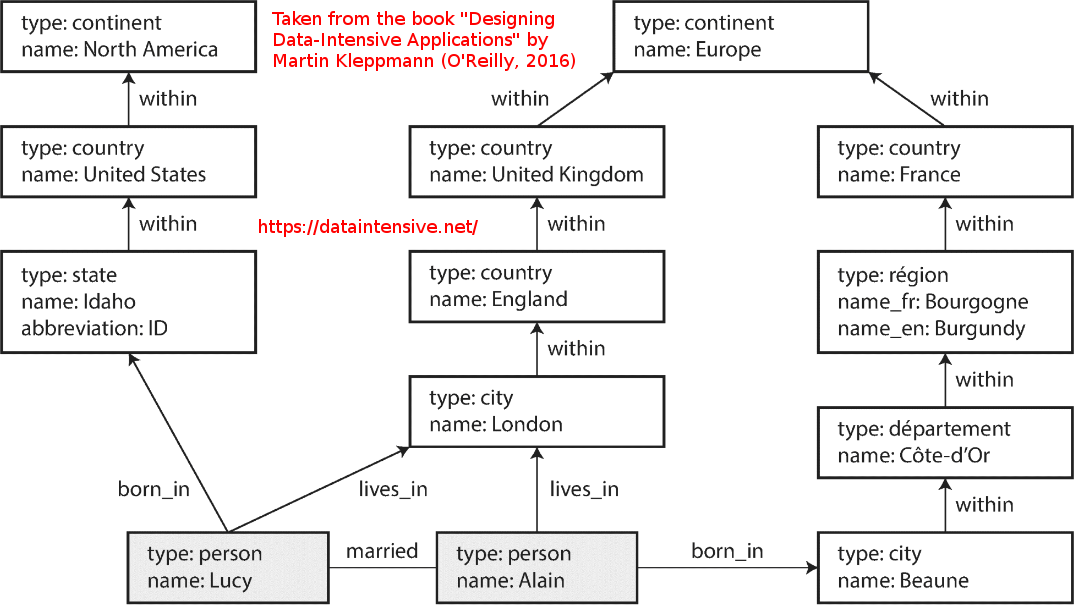
그래프는 속성(Property) 그래프 모델과 트리플 저장소 모델이 있습니다. 각각의 특징에 대해서 간단히 살펴보겠습니다.
- 속성 그래프
- 정점
- 고유한 식별자
- outgoing 간선 집합
- incoming 간선 집합
- 속성 컬렉션(키-값 쌍)
- 간선
- 고유한 식별자
- 간선이 시작하는 정점(tail vertex)
- 간선이 끝나는 정점(head vertex)
- 두 정점 간 관계 유형을 설명하는 레이블
- 속성 컬렉션(키-값 쌍)
- 정점
- 트리플 저장소
- 모든 정보를 주어(subject), 술어(predicate), 목적어(object)의 three-part statements 형식으로 저장
- 주어는 그래프의 정점을 의미
- 목적어
- 서술어와 목적어는 주어 정점에서 속성의 키-값과 동등
- 예시 : (루시, 나이, 33)은 lucy가 가진 속성 {“나이”:33}과 동등
- 서술어는 그래프의 간선, 주어는 꼬리 정점, 목적어는 머리 정점
- 예시 : (루시, 결혼하다, 알랭)은 루시 -> 알랭에 간선 레이블은 결혼하다와 동일
- 서술어와 목적어는 주어 정점에서 속성의 키-값과 동등
이와 같이 그래프 모델의 경우 모든 데이터들이 잠재적으로 연관되어 있는 경우에 사용할 수 있습니다.
지금까지 다양한 데이터 모델에 대해 간략하게 살펴보았습니다. 애플리케이션에 요구사항에 맞춰 적합한 데이터 모델을 찾고 적용해야 합니다. 이번 장은 다뤄야 할 내용이 많아서 2개의 포스트로 나누어서 작성할 예정입니다.
References
- 데이터 중심 애플리케이션 설계
- https://notes.shichao.io/dda/ch2/
- http://pauldone.blogspot.com/2018/04/mongodb-graph-data-intensive-book.html