HBase 데이터 모델
이번 포스트에서는 HBase의 데이터 모델에 대해 살펴볼 예정입니다.
먼저 데이터 모델이란 무엇일까요? 데이터 모델이란 데이터를 인식하고 조작하는데 사용되는 모델을 말합니다.
데이터베이스를 사용하는 사람에게 데이터 모델은 데이터베이스 내의 데이터와 상호작용하는 방법을 이야기하는 것입니다.
HBase에서 데이터 모델을 어떻게 표현하는지 살펴보기 전에 HBase에서 사용하는 용어를 먼저 살펴보도록 하겠습니다.
HBase Data Model 용어 정리
HBase는 데이터를 테이블에 저장합니다. 테이블은 row와 column으로 구성되어 있습니다. 이러한 용어들은 관계형 데이터베이스와 매우 유사한 것으로 보입니다. HBase에서 데이터를 저장하는 테이블의 형태는 아래와 같습니다.
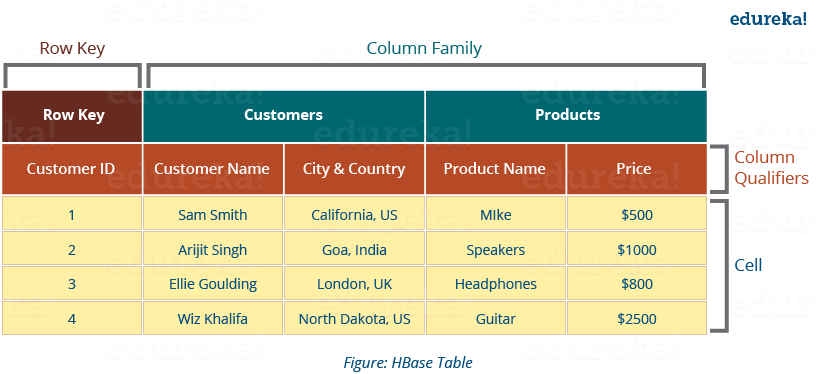
하지만 HBase의 데이터 모델이 관계형 데이터베이스의 데이터 모델로 보는 것은 HBase의 데이터 모델을 이해하는데 도움이 되지 않습니다. 오히려 아래의 그림과 같이 HBase 테이블을 다차원을 가진 맵의 자료구조로 생각하는 것이 도움이 됩니다.
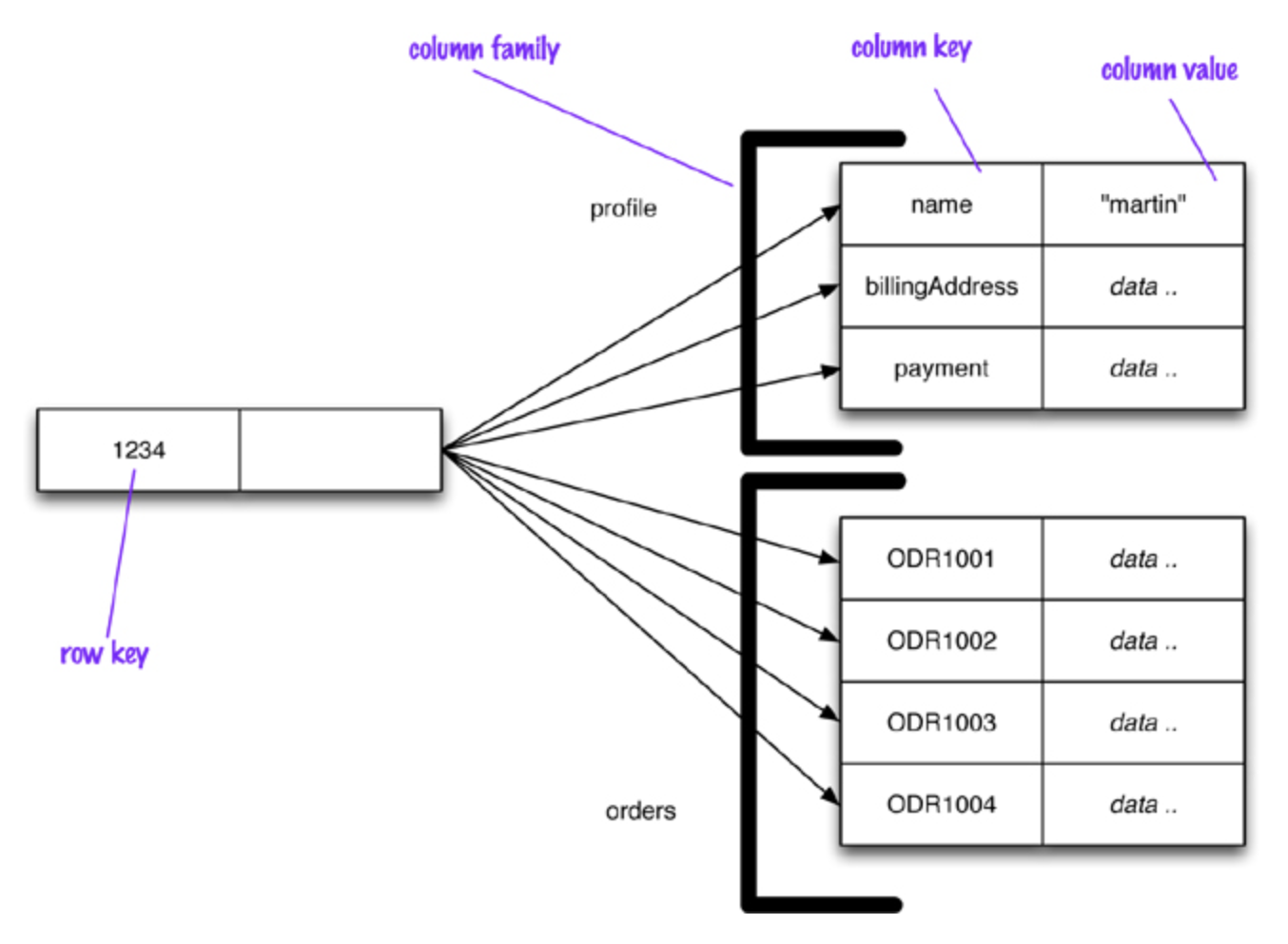
그러면 HBase에서 데이터 모델을 나타내기 위해서 사용하는 용어에 대해 살펴보도록 하겠습니다.
Table
- table은 여러개의 Row로 구성되어 있습니다.
Row
- row는 하나의 row key와 하나 이상의 column으로 구성됩니다.
- row는 row key의 이름 순으로 정렬되어 저장됩니다.
- 이러한 이유로 row key 디자인이 굉장히 중요합니다.
- row key를 디자인하는 방법은 공식 홈페이지에서 확인할 수 있습니다.
Column
- column family와 column qualifier로 구성되며
:으로 구분합니다.
Column Family
- column family는 HBase가 실제 데이터를 저장하는 물리적인 처리 방식과 관련있고 성능에 영향을 줍니다.
- 즉, disk i/o를 위해 column family내의 컬럼들을 disk 내에 물리적으로 가깝게 저장합니다.
- 이러한 이유로 column family는 미리 정의되어야 하고 쉽게 변경될 수 없습니다.
- 각각의 column family는 저장과 관련된 속성이 존재합니다.
- 예를 들어, 메모리에 캐시, 압축, row key 인코딩 등이 이에 해당합니다.
- table 내의 각각의 row는 동일한 column family를 가지고 있습니다.
Column Qualifier
- column qualifier는 column family와 다르게 사전에 정의될 필요가 없이 유동적입니다.
- 즉, row 사이에 항상 같을 필요는 없습니다.
- 예를 들어, column family가
content일 때, rowkey1은 content:html이라는 qualifier를 가지고, rowkey2는 content:pdf를 가질 수 있으며 서로 다른 qualifier를 가질 수 있습니다.
Cell
- 실제 저장된 값을 의미합니다.
- row key, column family, column qualifier의 조합을 Cell의 값을 식별할 수 있습니다.
- 실제 값은 timestamp 별로 여러 개가 존재할 수 있습니다.
Timestamp
- value와 함께 저장됩니다.
- cell의 값을 저장할 때 버전별로 저장하는데 이러한 버전은 timestamp로 식별됩니다.
- cell의 버전의 개수는 설정을 통해 변경 가능합니다.
HBase에서는 위에서 설명한 컨셉들이 기본이 됩니다. 실제 HBase에서 제공하는 API는 위의 6개의 조합을 통한 논리적인 뷰를 통해 접근할 수 있습니다.
지금까지 살펴본 용어에 대해 정확히 알면 HBase를 이해하는데 큰 도움이 됩니다.
HBase Conceptual View
HBase의 논리적인 뷰를 살펴보겠습니다. 먼저 하나의 샘플 테이블에 대해 살펴보겠습니다. 이 테이블은 HBase 공식 문서에 나와있는 예제입니다. 테이블 이름은 webtable이고 2개의 로우(com.cnn.www, com.example.www)가 있습니다. 컬럼 패밀리는 3개가 있으며 컬럼 패밀리 이름은 contents, anchor, people 입니다.
| Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor | ColumnFamily people |
|---|---|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” | ||
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” | ||
| “com.cnn.www” | t6 | contents:html = “…” | ||
| “com.cnn.www” | t5 | contents:html = “…” | ||
| “com.cnn.www” | t3 | contents:html = “…” | ||
| “com.example.www” | t5 | contents:html = “…” | people:author = “John Doe” |
위의 com.cnn.www는 버전이 5개입니다. com.example.www는 버전이 1개입니다. 위의 테이블은 비어있는 곳이 존재합니다. 이것을 보통 sparse한 테이블이라고 표현합니다. 논리적으로 보았을 땐 비어있는 것 같지만 HBase에서 실제로 데이터를 저장할 때는 빈 공간이 생기지 않습니다. 이렇게 테이블만 보았을땐 기존의 관계형 데이터베이스의 테이블과 유사합니다. 그러나 테이블의 형태로 보는건 논리적으로 보기 위한 것이고 실제로는 Multi-demensional map으로 생각하는 것이 HBase의 데이터 모델을 이해하기 쉽습니다. 위의 논리적인 테이블을 다차원 맵으로 바꾼다면 아래와 같습니다.
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}
HBase Physical View
HBase의 물리적인 뷰에 대해 살펴보겠습니다. 논리적인 뷰와 다르게 실제로 데이터를 저장할 때는 컬럼 패밀리 단위로 저장합니다. 위에선 살펴본 테이블의 anchor 컬럼 패밀리는 다음과 같이 저장합니다.
| Row Key | Time Stamp | Column Family anchor |
|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” |
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” |
contents 컬럼 패밀리 역시 아래와 같이 저장합니다.
| Row Key | Time Stamp | ColumnFamily contents: |
|---|---|---|
| “com.cnn.www” | t6 | contents:html = “…” |
| “com.cnn.www” | t5 | contents:html = “…” |
| “com.cnn.www” | t3 | contents:html = “…” |
HBase는 위와 같이 컬럼 패밀리 별로 하나의 파일에 데이터를 저장합니다.
HBase Data coordinate
기존의 로우와 칼럼을 기반으로 하는 관계형 데이터베이스는 2단계 코디네이트 시스템입니다. 그러나 HBase의 경우 4단계 코디네이트 시스템입니다. 코디네이트들은 순서대로 로우키, 컬럼 패밀리, 컬럼 한정자, 버전입니다. 해당 순서로 원하는 데이터에 접근을 할 수 있습니다.
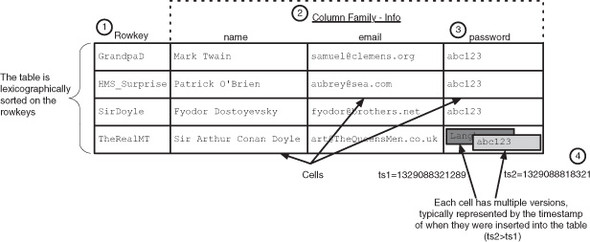
위의 그림에서 abc123이라는 값에 접근하기 위해서는 (TheRealMT, info, password, 1329088818321)을 통해 접근할 수 있습니다.
이와 같이 HBase는 코디네이트인 (TheRealMT, info, password, 1329088818321)를 키로, 그리고 실제 데이터인 abc123을 값으로 하는 키 밸류 저장소로 볼 수 있습니다.