Introduction to Kafka
1. Apache Kafka
아파치 카프카(이하 카프카)는 여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메시징 시스템입니다.
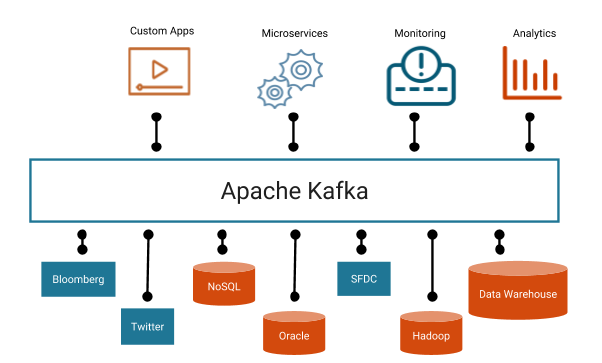
카프카는 여러 시스템과 장치를 연결하는 중요한 역할을 수행합니다. 카프카는 높은 처리량과 실시간 처리를 할 수 있습니다. 이러한 카프카는 다음의 4가지 특징을 가지고 있습니다.
- 확장성 : 여러 서버로 scale out 구성이 가능합니다.
- 영속성 : 수신한 데이터를 디스크에 유지하므로 데이터의 영속성을 유지합니다.
- 유연성 : 다양한 제품들을 연결할 수 있어서 시스템을 연결하는 허브 역할을 수행할 수 있습니다.
- 신뢰성 : 메시지 전달을 보증하므로 데이터 분실을 걱정하지 않아도 됩니다.
2. 카프카 설계 목표
카프카는 2011년 링크드인에서 출발하였습니다. 처음의 카프카는 링크드인 웹사이트에서 생성되는 로그를 처리하기 위해 개발하였습니다. 카프카를 설계할 당시 카프카의 실현 목표는 다음과 같습니다.
- 높은 처리량으로 실시간 처리
- 임의의 타이밍에 데이터를 읽음
- 다양한 프로덕트와 쉽게 연동
- 메시지를 잃지 않음
2.1 카프카 이전 제품
물론 이전에도 이러한 카프카의 요구사항을 충족하는 제품들이 있었지만 부분적으로 충족하는 경우가 대부분이고 포괄적으로 해결할 수 있는 제품은 없었습니다.
-
메시지 큐
기존의 메시지 큐를 활용할 수 있었지만 기존의 메시지의 경우는 위의 요구사항을 만족하지 않았습니다. 기존의 메시지 큐의 경우는 메시지를 정확히 한번만 전송(exactly once)되는 것을 보증할 수 있었습니다. 그러나 엄격한 트랜잭션 관리는 다소 오버 스펙이었으며 높은 처리량이 우선순위가 더 높았습니다. 또한 기존의 메시지큐는 스케일 아웃 기능을 대부분이 지원하지 않았습니다. 또한 메시지가 대량으로 쌓이는 것을 예상하지 않았고 배치로 처리하는 것을 고려하지 않았기 때문에 메시지 큐로는 한계가 있었습니다.
-
로그 수집 시스템
기존의 로그 수집 시스템의 경우 Flume이 대표적인 제품이었는데 HDFS로 데이터 축적하는 것과 배치 처리만 고려하였습니다.
2.2 카프카의 요구사항 실현
위에서 작성된 요구사항을 카프카에서 어떻게 실현했는지 살펴보겠습니다.
- 높은 처리량으로 실시간 처리 => 메시징 모델과 스케일 아웃형 아키텍처
- 임의의 타이밍에 데이터를 읽음 => 디스크로 데이터 저장
- 다양한 프로덕트와 쉽게 연동 => 이해하기 쉬운 API 제공
- 메시지를 잃지 않음 => 전달 보증 메커니즘
물론 요구 사항과 실현 수단이 일대일로 대응되지 않지만 핵심은 메시징 모델과 스케일 아웃형 아키텍처와 디스크로 데이터 영속화라고 할수 있습니다.
2.2.1 카프카 메시징 모델
카프카 메시징 모델은 다음과 같은 3가지 요소로 구성됩니다.
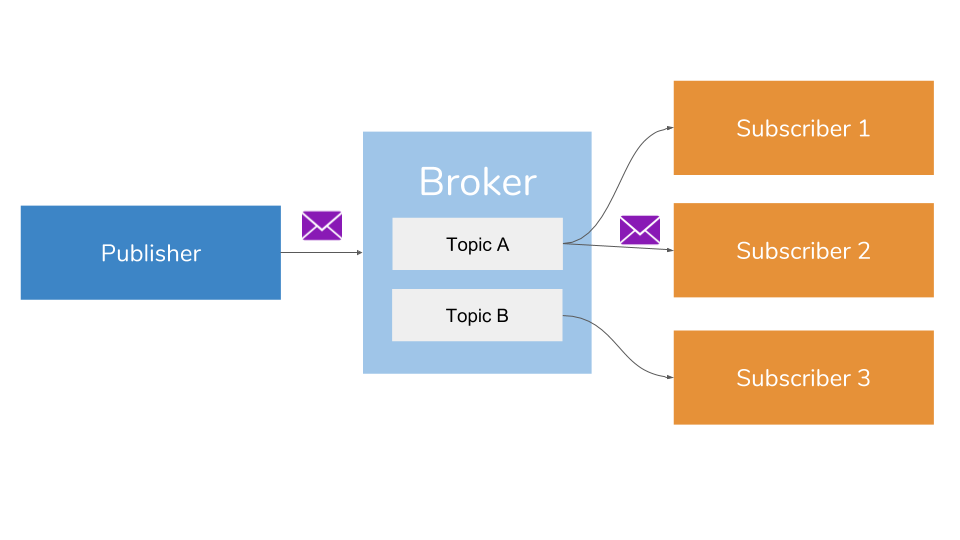
- 프로듀서 : 메시지 생산자
- 브로커 : 메시지 수집/전달 역할
- 컨슈머 : 메시지 소비자
카프카에서는 여러 컨슈머가 분산 처리로 메시지를 소비하는 큐잉 모델과 여러 서브스크라이버에서 동일한 메시지를 전달하고, 토픽 기반으로 전달 내용을 변경하는 펍/섭 모델로 메시징 모델을 구현하였으며, 컨슈머 그룹이라는 개념을 도입하여 컨슈머를 확장 구성할 수 있도록 설계하였습니다.

여러 컨슈머가 동일 토픽을 분산하여 메시지를 읽음으로써 처리 확장성을 제공합니다.
2.2.2 디스크로 데이터 영속화
카프카는 위에서 설명한대로 임의의 타이밍에 데이터를 읽고 메시지를 잃지 않기 위해서 메시지를 디스크에 저장합니다. 기존의 메시지 큐의 경우는 데이터를 메모리에 유지하였지만 실시간 처리에 중점을 두고 있는 경우가 많고 장기 보존을 가정하지 않았습니다. 그러나 카프카의 경우 데이터를 기간마다 모아 배치 처리도 고려했기 때문에 데이터를 메모리에 유지하는 것은 어려움이 있었습니다. 그래서 카프카의 메시지는 디스크에 저장하도록 구성하였습니다. 카프카의 특징은 디스크에 데이터를 저장함에도 불구하고 높은 처리량을 제공합니다. 후에 기회가 되면 디스크에 저장하면서 어떻게 높은 처리량을 제공할 수 있었는지를 포스트하도록 하겠습니다.
2.2.3 다양한 커넥터 제공
위의 특징에서 살펴보았듯이 카프카는 프로듀서와 컨슈머를 쉽게 접속할 수 있는 Connect API를 제공합니다. 이 API를 기반으로 카프카에 접속하기 위한 Kafka Connect를 제공하고 있습니다. 현재 컨플루언트에서는 다양한 제품을 지원하는 커넥터를 제공합니다. 또한 커뮤니티에서 제공하는 커넥터도 다양합니다. 이와같이 다양한 제품을 지원하므로써 데이터를 쉽게 연결할 수 있는 특징을 가지고 있습니다.
2.2.4 메시지 전달 보장
메시지 전달 방식에는 At Most Once, At Least Once, Exactly Once가 있으며 카프카에서는 3가지 수준으로 전달을 보장합니다. 각각의 특징은 아래의 표와 같습니다.
| 종류 | 개요 | 재전송유무 | 중복 삭제 유무 | 비고 |
|---|---|---|---|---|
| At Most Once | 1회 전달 시도 | X | X | 메시지는 중복되지 않지만 상실될 수 있음 |
| At Least once | 적어도 1회는 전달 | O | X | 메시지가 중복될 가능성은 있지만, 상실되지는 않음 |
| Exactly Once | 1회만 전달 | O | O | 중복되거나 상실되지도 않고 확실하게 메시지가 도달하지만, 성능이 나오지 않음 |
At Least Once
일반적으로 메시지 큐에서는 Exactly Once 수준을 제공하는 것을 목적으로 합니다. 카프카의 개발 초기에는 높은 처리량을 목적으로 했기 때문에 At Least Once 수준의 전달의 보장했습니다.
At Least Once의 경우 Ack와 Offset Commit을 통해서 제공했습니다. Ack는 프로듀서에게 수신에 대한 응답을 뜻합니다.
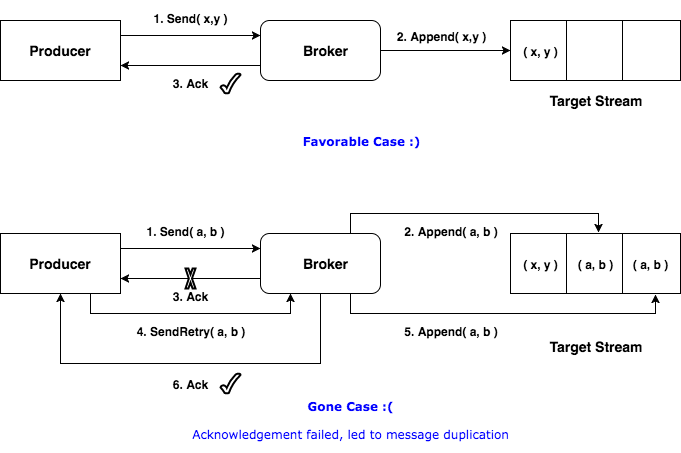
마찬가지로 컨슈머가 브로커로 메시지를 받을 때 어디까지 메시지를 받았는지 관리하기 위한 오프셋이 존재합니다. 이를 이용한 전달 보장 구조를 오프셋 커밋이라고 합니다. Ack와 비슷한 역할을 수행하고 있는 것이죠.
Exactly Once
카프카의 사용자가 늘어나면서 Exactly Once의 요구사항이 많아졌습니다. 그래서 카프카에서는 트랜잭션 개념을 도입하여 Exactly Once를 보장합니다. Exactly Once는 (프로듀서와 브로커), (브로커와 컨슈머) 사이의 서로 구현이 필요합니다. 프로듀서와 브로커 사이에 양쪽 모두에서 시퀀스 번호를 관리해 중복되는 실행을 제거하는 방법을 사용합니다. 멱등성을 유지하는 프로듀서라는 의미에서 Idempotent Producer라고 합니다.
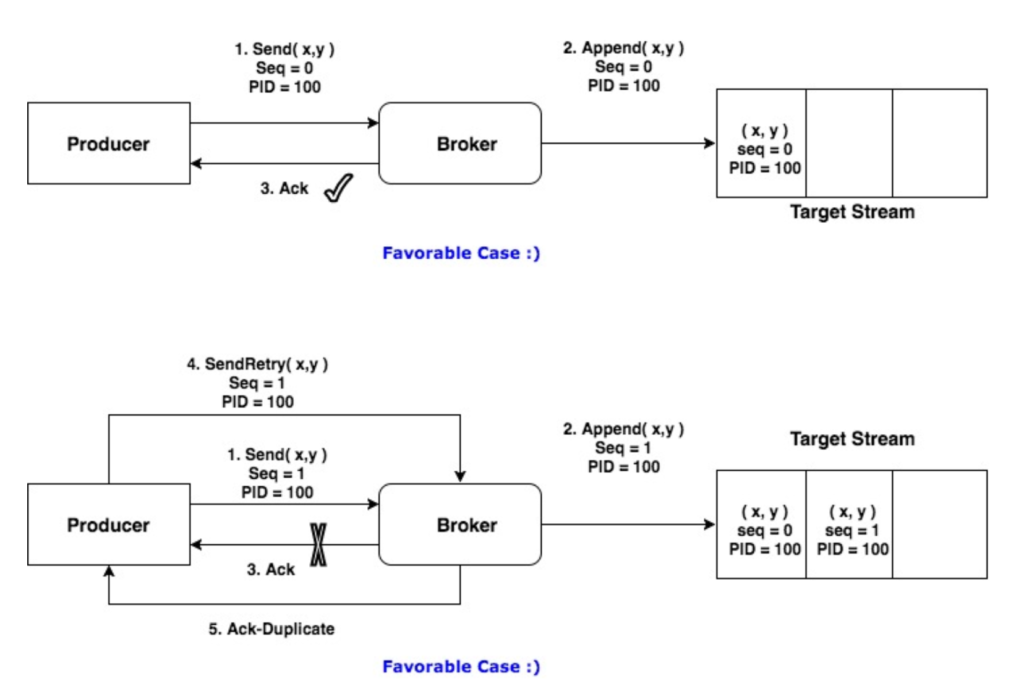
브로커와 컨슈머 간에는 컨슈머에 대해 트랜잭션 관리 메커니즘을 제공해서 Exactly Once를 제공합니다. 이와 같이 Exactly Once를 보장하려면 카프카 뿐만 아니라 프로듀서와 컨슈머에서도 상태 관리가 필요합니다.