파티셔닝(Partitioning) - 1
데이터셋이 매우 크거나 질의 처리량이 매우 높은 경우 데이터를 파티션으로 쪼개야 합니다. 이번 포스트에서 이야기하는 파티셔닝은 대용량 데이터베이스에서 데이터를 작은 단위로 쪼개는 방법을 말합니다. 몽고DB, 엘라스틱서치, 솔라에서는 샤드라고 하며 HBase에서는 리전, 빅테이블에서는 태블릿(tablet), 카산드라와 리악에서는 vnode, 카우치베이스에서 vBucker이라고 부릅니다. 데이터 파티셔닝의 가장 큰 목적은 확장성을 갖기 위함입니다. 대용량 데이터셋을 파티셔닝하여 여러 디스크에 분산시킬 수 있고, 질의 부하를 분산시킬 수 있습니다.
주로 파티셔닝은 복제(Replication)와 함께 적용해 파티션의 복사본을 여러 노드에 저장합니다. 복제에 관한 설명은 이전 포스트에서 확인할 수 있습니다. 파티셔닝된 데이터를 복제함으로써 내결함성을 보장할 수 있게 됩니다. 일반적인 리더-팔로워 복제 모델을 사용하면 파티셔닝과 복제의 조합은 다음 그림과 같습니다.
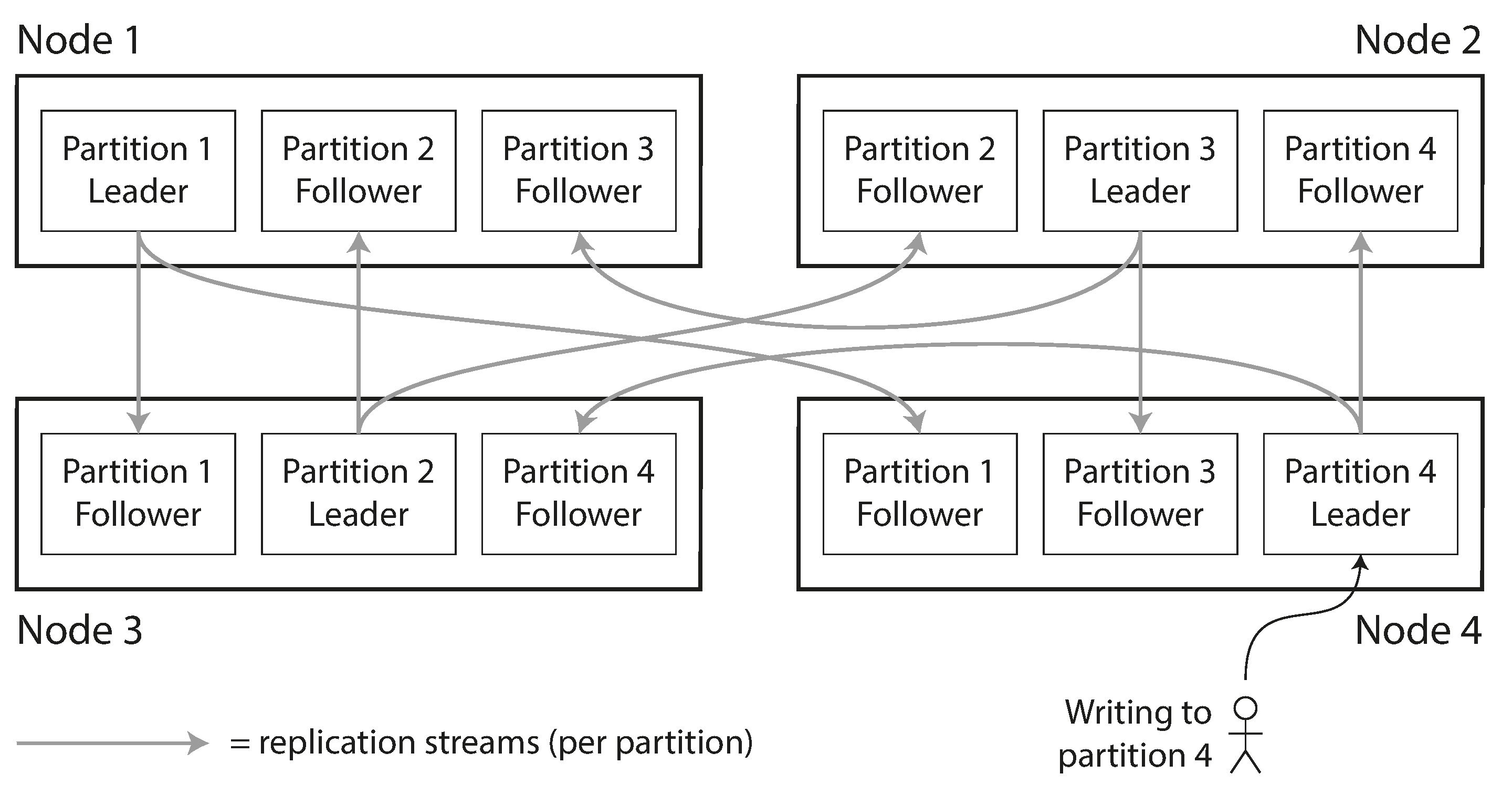
키-값 데이터 파티셔닝
키-값 데이터 모델을 사용한다고 가정했을 때, 이 모델에서는 기본키를 통해 레코드에 접근합니다.
범위 키 파티셔닝
각 파티션에 연속된 범위를 키에 할당하는 방법입니다. 가장 대표적인 예가 아래의 그림과 같이 종이 백과사전이 되겠습니다. 각 범위들 사이의 경계를 알면 어떤 키가 어느 파티션에 속하고 있는지 쉽게 찾을 수 있습니다. 또한 어떤 파티션이 어느 노드에 할당되어 있는지 알면 적절한 노드로 요청을 직접 보낼 수 있습니다. 백과사전의 경우 책장에서 알맞는 책을 꺼낼 수 있는 것과 같습니다.

키 범위의 크기가 동일할 필요는 없습니다. 데이터가 고르게 분포가 되지 않을 경우도 있기 때문입니다. 위 그림의 예에서 보듯이 1권의 경우 A-B까지 범위이지만 마지막 권의 경우 T-Z로 범위가 더 넓습니다. 이와 같이 데이터를 고르게 분산시키려면 파티션 경계를 데이터에 맞게 조정해야 합니다. 파티션 내에서 키를 기준으로 정렬된 순서로 저장할 수 있는데 이렇게 하면 범위 스캔이 쉬워지는 장점을 갖습니다. 또한 키를 연결된 인덱스로 간주해서 질의 하나로 관련 레코드를 여러개를 읽어오는데 사용할 수 있습니다. 키 범위 파티셔닝의 경우 핫스팟(불균형하게 부하가 높은 파티션)이 발생할 수 있는 단점이 있습니다. 이 경우에는 애플리케이션의 특성에 맞춰서 파티셔닝의 키 선택을 해야 합니다.
해시 키 파티셔닝
주로 분산 데이터스토어는 쏠림과 핫스팟 문제 때문에 키의 파티션을 정하는데 해시 함수를 많이 사용합니다. 이 기법은 키를 파티션 사이에 균일하게 분산시킬 수 있는 장점을 갖습니다.
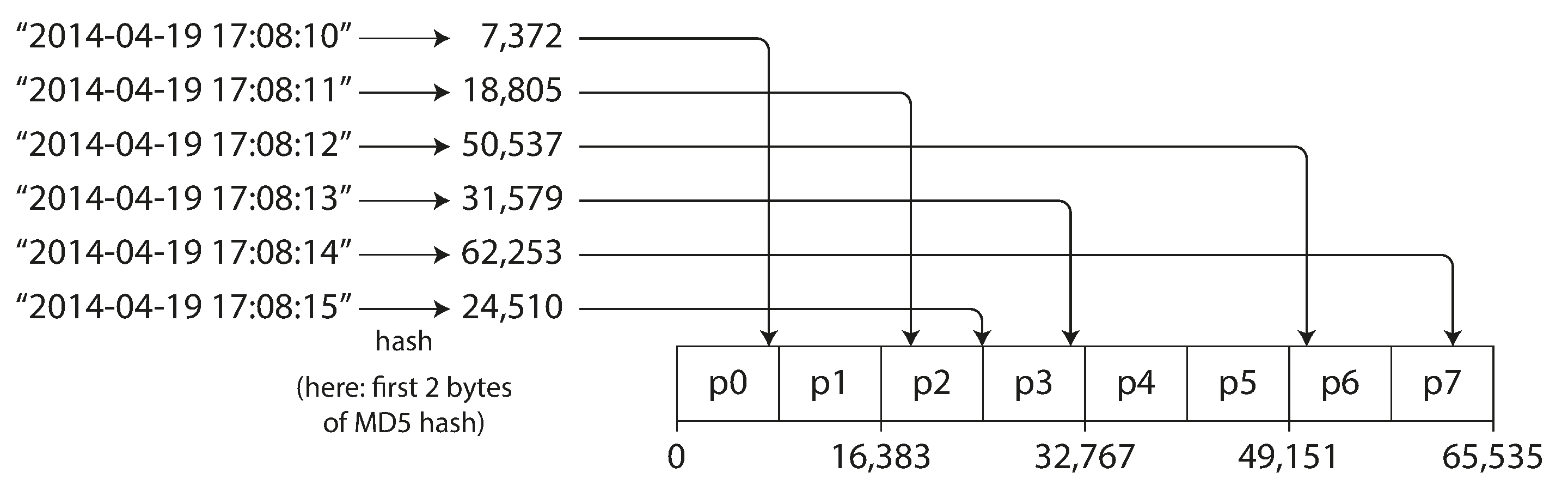
해시 파티셔닝의 경우 범위 파티셔닝에서 범위 질의를 효율적으로 실행할 수 있는 장점을 잃어 버립니다. 범위 파티셔닝에서 인접했던 키들이 모든 파티션에 흩어져서 정렬 순서가 유지되지 않기 때문입니다.
쏠린 작업 부하와 핫스팟 완화
해시 기반의 파티셔닝을 하면 핫스팟을 줄일 수 있지만 완전히 제거할 수 없습니다. 만약 항상 동일한 키를 읽고 쓰는 극단적인 상황에서는 모든 요청이 동일한 파티션으로만 쏠리게 됩니다. 이러한 경우 애플리케이션에서 쏠림을 완화해야 하는데 주로 간단한 해결책은 각 키의 시작이나 끝에 임의의 숫자를 붙여서 해당 키를 여러 파티션으로 분산시키는 방법입니다. 대신에 이와 같이 하나의 키를 쪼개서 쓰게 되면 읽기를 실행할 때 추가적인 작업이 필요합니다. 예를 들어 하나의 키를 100개로 나누었을 때 나누어진 데이터를 모아서 처리해야 하기 때문입니다. 그리고 추가적으로 저장해야 할 정보도 있기 때문에 요청이 몰리는 소수의 키에서만 사용해야 합니다. 낮은 쓰기 처리량을 가진 키에도 적용하면 불필요한 오버헤드가 발생하기 때문입니다.
파티셔닝과 세컨더리 인덱스
세컨더리 인덱스는 레코드를 유일하게 식별하는 용도가 아닌 특정한 값이 발생한 항목을 검색하는 수단입니다. 키-값 데이터 모델에서는 레코드를 기본키를 통해서만 접근하므로 키를 기준으로 파티션을 결정할 수 있습니다. 그러나 세컨더리 인덱스는 파티션에 깔끔하게 대응되지 않는 문제점을 갖습니다. 세컨더리 인덱스 기능을 제공하는 데이터베이스에서 파티셔닝하는데 널리 쓰이는 2가지 방법이 있습니다. 바로 문서 기반 파티셔닝과 용어 기반 파티셔닝입니다.
문서 기반 세컨더리 인덱스 파티셔닝
한가지 예를 통해 살펴보겠습니다. 중고차를 판매하는 웹사이트를 운영하고 있습니다. 차마다 문서 ID라는 고유의 ID가 있으며, 데이터베이스는 문서 ID를 기준으로 파티셔닝을 합니다. 사용자들이 차를 검색할 때 색상과 제조사로 필터링하는 기능을 제공하려면, color와 make(관계형 데이터베이스는 칼럼이라고 하고 문서 데이터베이스에서는 필드라고 함)에 세컨더리 인덱스를 만들어야 합니다. 인덱스로 설정을 하면 데이터베이스가 데이터가 추가될 때 자동으로 인덱스를 생성할 수 있습니다. 아래의 그림이 이와 같습니다.
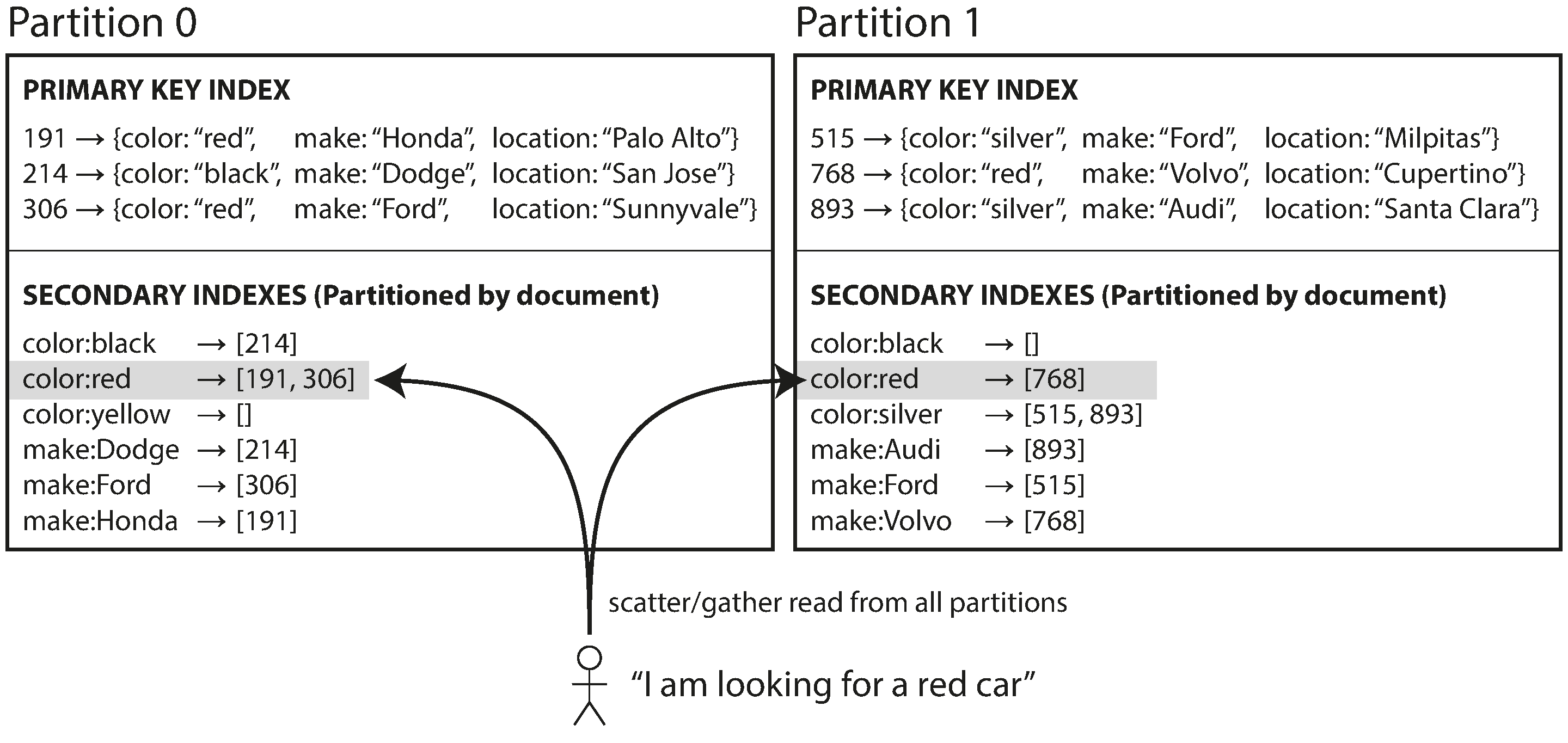
이러한 인덱싱 방법을 사용하면 각 파티션 별로 독립적으로 동작이 가능합니다. 각 파티션 별로 자신의 세컨더리 인덱스를 유지하며 그 파티션에 속하는 문서만 담당합니다. 그러한 까닭에 문서 파티셔닝 인덱스는 지역 인덱스(local)라고도 합니다.
일반적으로 특정한 색상이나 특정한 제조사가 만든 자동차가 동일한 파티션에 저장되지 않을 수 있으므로 빨간색 자동차를 찾고 싶다면 모든 파티션으로 질의를 보내서 결과를 모두 모아야 합니다. 파티셔닝된 데이터베이스에서 이런 식으로 질의를 보내는 방법을 scatter/gather라고 합니다. 이런 질의는 읽는 질의에 큰 비용이 발생할 수 있습니다. 그럼에도 불구하고 세컨더리 인덱스를 문서로 기준으로 파티셔닝하는 경우가 많습니다. 대표적으로 몽고DB, 리악, 카산드라, 엘라스틱서치, 볼트DB 등 입니다.
단어(term) 기반 세컨더리 인덱스 파티셔닝
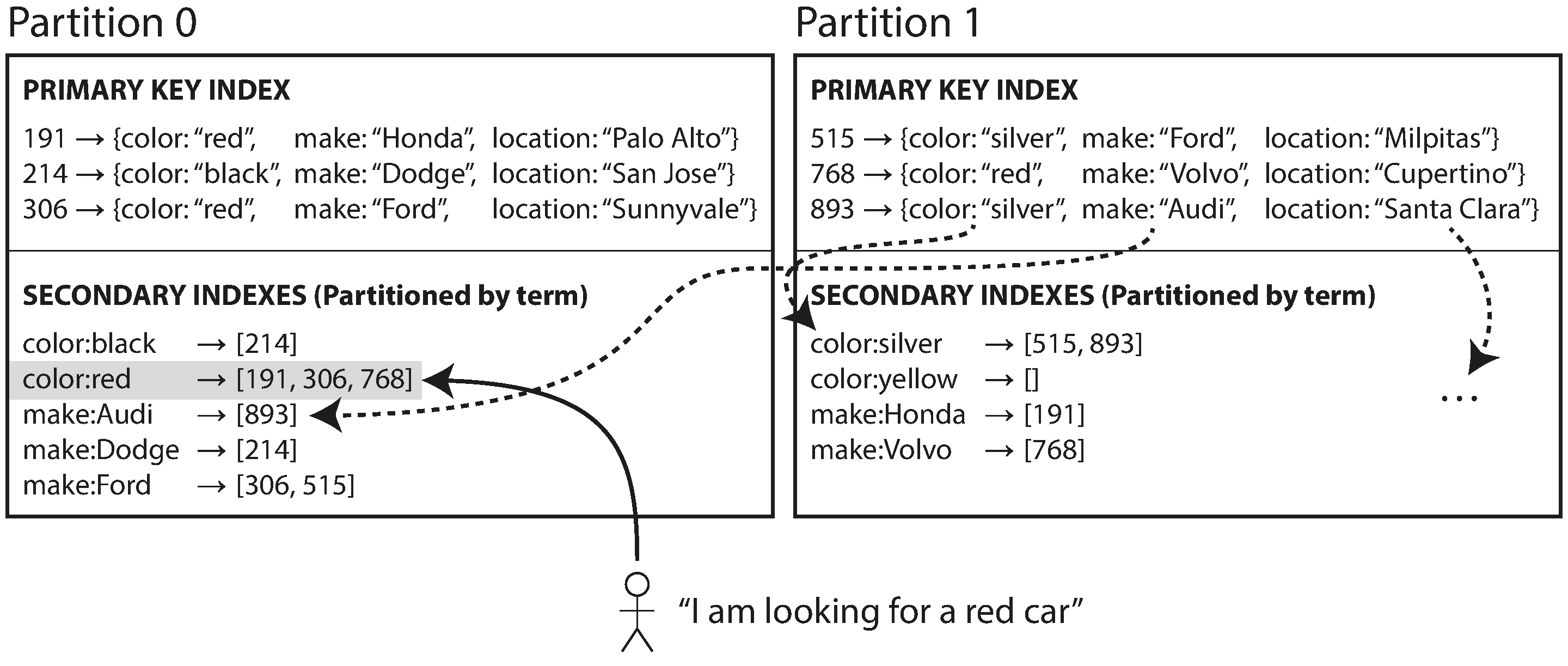
위의 그림을 통해 예를 살펴보겠습니다. 찾고자 하는 단어에 따라 인덱스의 파티션이 결정되므로 단어 기준으로 파티셔닝됩니다(term-partitioned). 색깔 인덱스의 경우 a-r 까지의 글자로 시작하는 색깔은 파티션 0에 s-z까지의 글자로 시작하는 색깔은 파티션 1에 저장되도록 파티셔닝되는 것입니다. 제조사도 마찬가지입니다. 여기서 단어는 전문 색인(full-text index)에서 온 것인데 단어(term)란 문서에 등장하는 모든 단어를 이야기합니다.
인덱싱을 할 때 단어 자체를 사용할 수 있고 단어의 해시값을 사용할 수 있습니다. 차이점은 앞에서 살펴봤듯이 단어 자체로 파티셔닝하면 범위 스캔이 가능합니다. 반면에 해시값을 사용하면 부하가 좀 더 고르게 분산되는 장점을 갖게 됩니다.
문서 기반 세컨더리 인덱스에 비해 전역 인덱스(단어 파티셔닝)이 갖는 이점은 읽기가 효율적이라는 것입니다. 용어 파티셔닝의 경우 모든 파티션에 scatter/gather를 실행할 필요 없이 원하는 단어를 포함하는 파티션으로만 요청을 보냅니다. 하지만 쓰기가 느리고 복잡하다는 단점을 갖습니다. 단일 문서를 쓸 때 문서에 있는 모든 단어가 다른 노드의 파티션에 속할 수 있기 때문입니다.
정리
이번 포스트에서는 두가지 주요 파티셔닝 기법인 범위와 해시 방식의 파티셔닝에 대해 알아보았습니다. 그리고 파티셔닝과 세컨더리 인덱스의 상호 작용에 관해 살펴보았습니다. 다음 포스트에서는 이어서 파티션 리밸런싱 기법과 라우팅 처리하는 방식에 관해 살펴보도록 하겠습니다.