파티셔닝(Partitioning) - 2
이전 포스트에 이어서 파티셔닝에서 사용하는 리밸런싱 기법에 관해 살펴보고, 클라이언트에서 질의 요청을 어떻게 처리할 것인지에 관해 알아보겠습니다.
파티션 리밸런싱
리밸런싱이란 클러스터에서 한 노드가 담당하던 부하를 다른 노드를 옮기는 과정입니다. 이러한 리밸런싱이 필요한 경우는 시간이 지나면서 데이터베이스에 변화가 생기기 때문입니다. 예를 들어 질의 처리량이 증가하여 부하를 늘리기 위해 CPU를 추가하거나, 데이터 셋의 크기가 증가하여 디스크와 램을 추가 하는 등의 변화입니다. 이러한 리밸런싱을 위한 전략이 몇가지가 있습니다.
리밸런싱 전략
쓰면 안되는 방법: 해시값 mod N
mod 연산을 사용하면 쉽게 각 키를 노드에 할당하는 것이 쉽다. 예를 들어 노드가 10대가 있고 hash(key) mod 10을 통해 0-9 사이의 숫자를 기반으로 해당 노드에 할당하는 방식이다. 처음엔 문제가 되지 않는다 그러나 노드가 1대 늘어나서 11대가 되는 경우 대부분의 키값들은 다른 노드로 옮겨져야 하기 때문에 리밸런싱 비용이 지나치게 커지는 문제가 발생한다.
고정 파티션 수
간단한 해결책으로 파티션의 개수를 고정하는 방법이 있습니다. 즉, 총 파티션의 개수를 고정해놓고 새로운 노드가 추가되는 경우에 파티션만 다시 분배시키는 방법입니다. 클러스터에서 노드가 제거 되면 이 과정이 반대로 수행됩니다. 이러한 과정을 나타내는 그림은 아래와 같습니다.
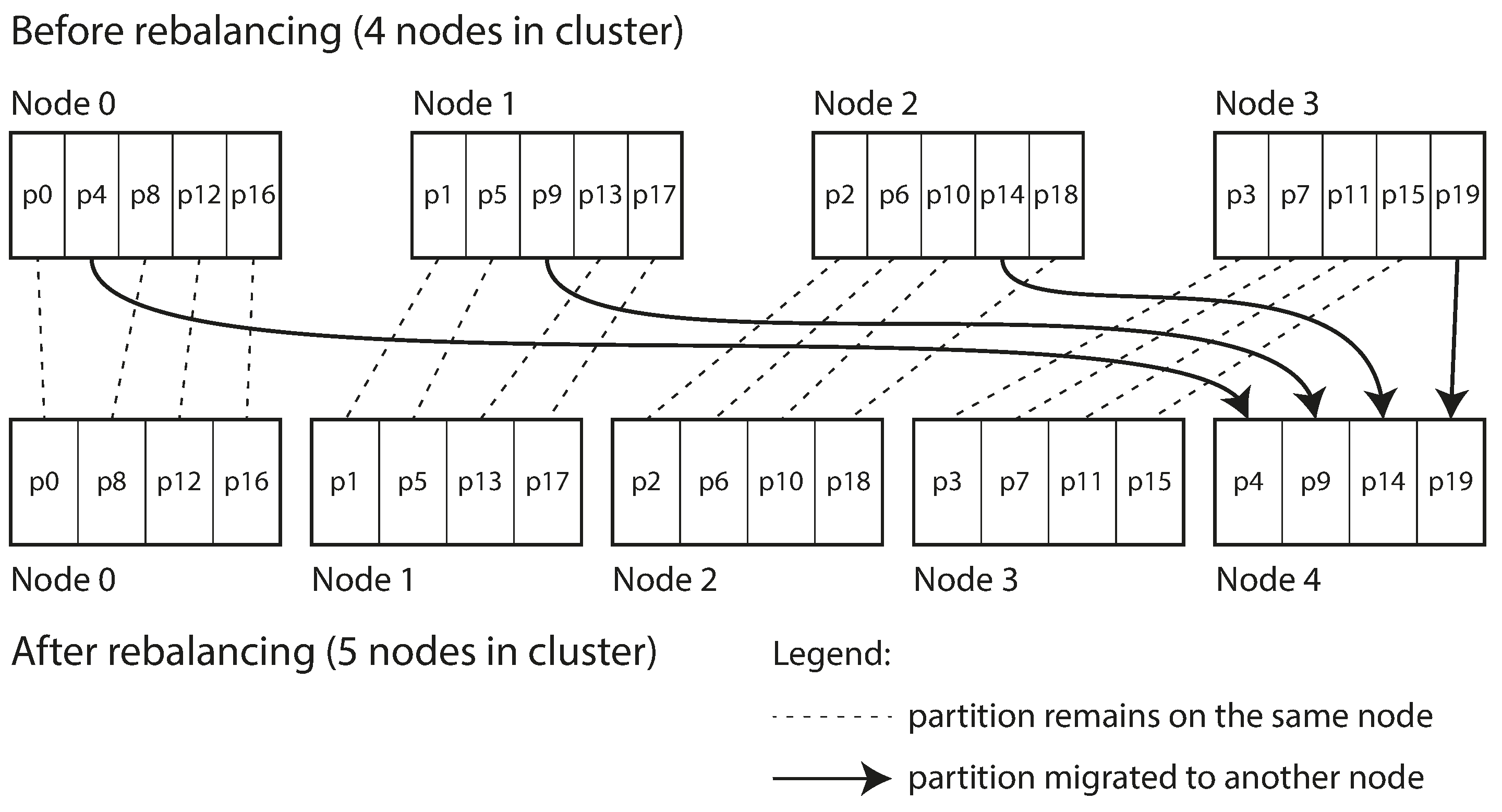
고정 파티션을 사용할 때 처음 설정된 파티션 개수가 사용가능한 노드 대수의 최대치가 되므로 미래에 충분히 수용가능하도록 설정해야 합니다. 너무 크거나 작은 경우에는 오버헤드가 발생할 수 있습니다. 사실 적당히 선택해야 하지만 적절한 크기를 찾기는 쉽지 않습니다. 결국 애플리케이션의 특성을 잘 파악하고 후에 얼마나 변할 것인지 잘 예측해서 정해야 하는 어려움이 있습니다.
동적 파티셔닝
범위 파티셔닝의 경우 파티션 경계를 잘못 지정하면 모든 데이터가 한 파티션에 저장되고 나머지 파티션은 빌 수 있습니다. 이 경우에 파티션 경계를 수동으로 재설정해야 하는데 고된 작업입니다. 이러한 이유 때문에 범위 파티셔닝을 사용하는 데이터베이스에서는 파티션을 동적으로 만듭니다. 예를 들어 파티션 크기가 설정된 값을 넘어서면 파티션을 두개로 쪼개고 반대로 데이터가 많이 삭제되어 파티션 크기가 임계값 아래로 떨어지면 인접한 파티션과 합쳐질 수 있습니다. 그러나 이러한 방식은 빈 데이터베이스부터 시작하는 경우 파티션 경계에 관한 사전 정보가 없으므로 시작할 때 파티션이 한개로 시작합니다. 파티션이 한개로 시작하면 나머지 노드들은 유휴 상태로 존재합니다. 이 문제를 해결하기 위해 HBase와 몽고DB에서는 빈 데이터베이스에 초기 파티션 집합을 설정할 수 있습니다. 이 방식을 pre-splitting이라고 합니다.
노드 비례 파티셔닝
파티션 개수가 노드 수에 비례하도록 하는 방법입니다. 즉, 노드당 할당되는 파티션 개수를 고정하는 방식입니다. 노드 수가 변함 없는 동안 개별 파티션 크기가 데이터셋의 크기에 비례해서 증가 하지만, 노드 수를 늘리면 파티션 크기는 작아지도록 하는 방식입니다. 이 방식을 채택하고 있는 대표적인 데이터베이스는 카산드라입니다.
라우팅 요청
클라이언트에서 요청을 보내려고 할 때 어느 노드에 접속해야 하는지 어떻게 알 수 있을까요? 아래의 그림과 같이 3가지 방식이 있습니다.
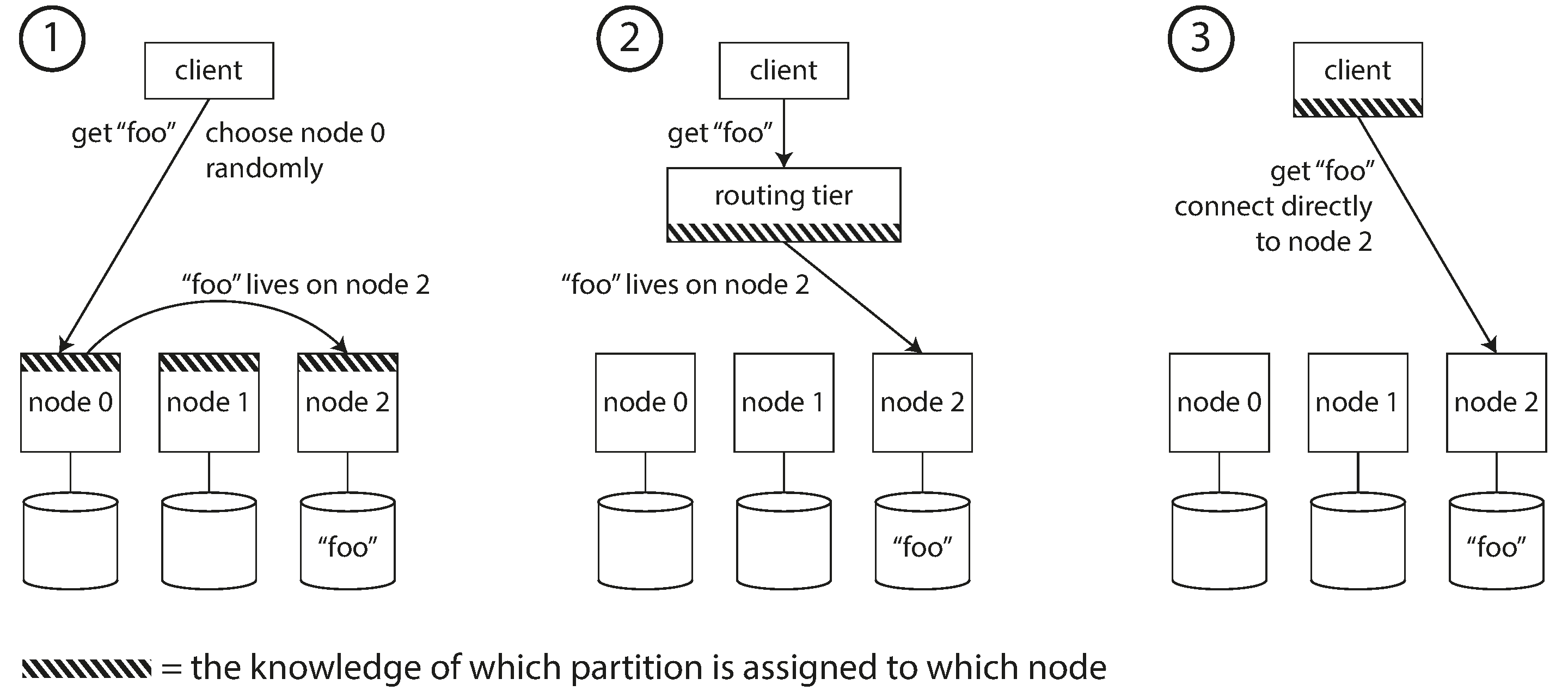
- 클라이언트가 아무 노드에 접속하고 해당 노드에 파티션이 존재하면 직접 처리하고 아니면 요청을 올바른 노드로 전달해서 응답을 받아서 돌려주는 방법
- 클라이언트가 모든 요청을 라우팅 계층으로 보내는 방법
- 클라이언트가 파티셔닝 방법과 파티션이 어떤 노드에 할당됐는지 알고 있어서 직접 처리하는 방법(partition-aware)
여기서 가장 중요한 문제는 라우팅 결정을 내리는 구성요소가 노드에 할당된 파티션의 변경 사항을 어떻게 알 수 있느냐 입니다. 이와 같은 문제는 라우팅을 요청 받는 곳에서 정보가 일치해야 합니다. 주로 분산 데이터 시스템은 클러스터의 메타데이터 추석을 위해 주키퍼와 같은 코디네이션 서비스를 이용합니다. 파티션 소유자가 변경되거나 노드가 추가, 삭제 되는 경우 주키퍼는 라우팅 계층에 이를 알려줘서 라우팅 정보를 최신으로 유지합니다.
정리
이번 포스트에서는 대용량 데이터셋을 파티셔닝하는 다양한 방법을 살펴보았습니다. 먼저 주요 파티셔닝 방식인 범위 파티셔닝과 해시 파티셔닝에 관해 살펴보았습니다. 그리고 파티셔닝과 세컨더리 인덱스 사이의 상호 작용에 관해 알아보았습니다. 끝으로 라우팅 기법도 살펴보았습니다. 이러한 파티셔닝 방법을 통해서 대용량 데이터를 여러 장비에 처리를 할 수 있습니다. 핫스팟이 생기지 않고 질의 부하를 여러 장비에 균등하게 분배할 수 있도록 데이터에 적합한 파티셔닝 방식을 선택하여 사용해야 합니다.