저장소(Storage)와 검색(Retrieval) - 1
이전 포스트에서는 데이터 모델과 질의 언어에 대해 알아보았습니다. 예를 들어 애플리케이션 개발자 관점에서 데이터베이스에 저장하는 데이터 포맷과 데이터를 다시 요청하는 메커니즘과 같은 것들을 살펴보았습니다. 이번 장에서는 데이터베이스 관점에서 데이터를 저장하는 방법과 데이터를 요청했을 때 다시 찾을 수 있는 방법에 대해서 살펴볼 예정입니다.
일반적으로 애플리케이션 개발자는 처음부터 자신의 저장소 엔진을 구현하기 보다는 사용가능한 저장소 엔진 중에 애플리케이션 요구사항에 적합한 데이터 모델을 처리할 수 있는 저장소 엔진을 선택합니다. 특정 작업부하(workload) 유형에서 좋은 성능을 내도록 저장소 엔진을 조정하려면 어느 정도 저장소 엔진의 내부적인 이해가 필요합니다. 일반적으로 트랜잭션 작업 부하에 최적화된 저장소 엔진과 분석을 위해 최적화된 엔진간의 큰 차이가 있습니다. 또한 익숙한 데이터베이스 종류인 관계형 데이터베이스와 NoSQL이라고 불리는 데이터베이스에 사용되는 저장소 엔진에 대해서 살펴볼 예정입니다. 그리고 로그 구조(log-structured) 계열 저장소 엔진과 B-tree와 같은 페이지 지향(page-oriented) 계열 저장소에 대해서도 살펴보겠습니다.
데이터베이스를 강력하게 만드는 데이터 구조
가장 간단한 데이터베이스를 만들어보겠습니다. 이 데이터베이스는 2개의 bash 함수로 구현합니다.
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
key-value 저장소를 함수 두 개로 구현하였습니다.
db_set key value
db_set를 호출하면 데이터베이스에 key, value를 저장합니다. db_get key를 호출하면 해당 키의 가장 최근 값을 찾아 반환합니다. 그럼 이 데이터베이스의 사용 예는 다음과 같습니다.
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
저장 포맷은 매우 간단합니다. 한 라인에 쉼표로 구분하여 key-value를 저장하는 텍스트 파일입니다. db_set은 호출할 때마다 파일 끝에 key-value를 추가합니다. 파일을 끝에 추가하므로 여러번 갱신해도 이전 버전을 덮어쓰지 않습니다. 최신 데이터를 찾기 위해서는 파일에서 키의 마지막 항목을 살펴 봐야합니다. 그래서 위의 db_get에서 tail -n 1을 실행합니다. 키 값이 42인 데이터를 하나 더 추가 후 데이터를 가져오고, 데이터베이스 파일에 저장된 값을 살펴보도록 하겠습니다.
$ db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
$ cat database
123456,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}
db_get 함수에서는 가장 최근에 넣은 값이 나오는 것을 알 수 있습니다. 위와 같이 db_set 함수를 사용하여 데이터를 추가하는 경우 파일을 추가 하는 일입니다. 이렇게 파일 추가 작업은 매우 효율적이기 때문에 실제로 꽤 좋은 성능을 보여줍니다. 그래서 많은 데이터베이스는 내부적으로 append-only 데이터 파일인 로그를 사용하고 있습니다. 실제 데이터베이스에선 위와 같이 간단하게 로그를 사용하진 않습니다. 예를 들어 로그에 대한 동시성 제어, 로그가 계속 커지지 않게끔 하는 처리, 오류 처리, 부분적으로 기록된 레코드 처리 등과 같은 것들이 있습니다. 그러나 로그의 기본 원리는 같습니다. 이와 같이 로그는 굉장히 유용합니다.
반면에 db_get 함수는 데이터베이스에 많은 레코드들이 있으면 성능이 매우 좋지 않습니다. 왜냐하면 키가 있는지 찾기 위해 매번 데이터베이스 파일을 full scan 해야 합니다. 검색 비용이 O(n)입니다. 즉, 데이터베이스의 레코드 수가 2배 늘면 찾는데도 2배 오래 걸립니다. 그래서 데이터베이스에서는 특정 키 값을 효율적으로 찾기 위해서 다른 자료구조가 필요합니다. 그래서 사용하는 자료구조는 바로 색인입니다.
색인은 일반적으로 부가적인 메타데이터를 유지하는 것입니다. 이 메타데이터를 통해 빠르게 원하는 데이터의 위치를 찾는 것이죠. 이러한 색인은 원래 데이터로부터 추가적으로 생성한 자료구조입니다. 이와 같은 추가적인 자료구조이므로 데이터를 쓰는 과정에서 추가적인 오버헤드가 생깁니다. 즉, 색인은 쓰기 속도를 느리게 만드는 대신 읽기를 빠르게 하는 역할을 하는 것입니다. 이것은 저장소 시스템에서 중요한 트레이드 오프입니다. 그렇기 때문에 애플리케이션 개발자는 애플리케이션에서 자주 사용하는 질의 패턴에 대해서 직접 색인을 선택해야 합니다. 그래야 필요 이상으로 오버헤드를 발생시키지 않으면서 애플리케이션에 이익을 가져다줄 수 있습니다.
해시 색인(Hash Index)
디스크 상의 데이터를 색인하기 위해 인메모리 데이터 구조인 해시 맵을 사용하는 예를 살펴보도록 하겠습니다. 앞의 예제와 같이 단순히 파일에 추가하는 방식으로 데이터 저장소를 구성하는 경우 가장 간단한 색인 전략은 키를 데이터베이스 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵에 유지하는 것입니다.
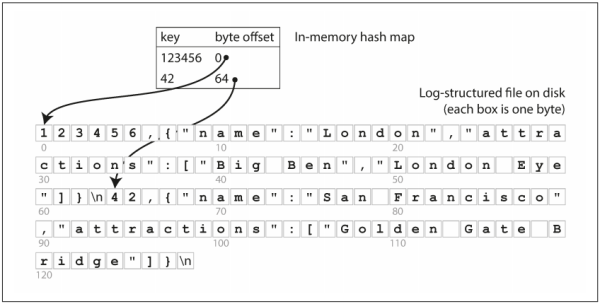
바이트 오프셋은 위의 그림과 같이 키를 통해 바로 값을 찾을 수 있습니다. 파일에 새로운 key-value 쌍이 추가될 때마다 해시 맵도 갱신해야 합니다.
지금까지 설명한 것과 같이 계속 파일에 추가만 하는 경우 디스크 공간이 부족해집니다. 이러한 문제를 해결하는 방법으로 특정 크기의 세그먼트로 로그를 나누는 것입니다. 즉, 파일이 특정 크기에 도달하면 세그먼트 파일을 닫고 새로운 세그먼트 파일에 추가를 하는 것입니다. 이러면 각각의 파일에 대해 컴팩션(compaction)을 수행할 수 있습니다. 컴팩션은 각 로그의 중복된 키 값을 버리고 각 키의 최신 값만 유지하는 것을 의미합니다. 이러한 세그먼트 파일은 변경할 수 없기 때문에 컴팩션을 통한 병합된 세그먼트는 새로운 파일로 만듭니다. 컴팩션의 경우 백그라운드 스레드에서 수행이 되며, 컴팩션을 수행하는 동안에도 사용자의 읽기나 쓰기 요청도 정상적으로 처리할 수 있습니다. 병합이 완료되면 새로 병합한 세그먼트를 사용하도록 전환하고 전환 후에는 이전 세그먼트 파일을 삭제합니다. 다음 그림은 컴팩션과 병합을 수행하는 과정을 나타낸 그림입니다.

위와 같은 형태로 세그먼트로 나누어 파일의 저장하는 경우 각 세그먼트 파일별로 인메모리 해시 테이블을 갖습니다. 그래서 키의 값을 찾으려면 최신 세그먼트 해시 맵을 확인하고 없으면 두 번째 최신 세그먼트의 확인이 필요합니다. 병합을 통해 세그먼트 수가 적게 유지되기 때문에 조회를 위해 많은 해시 맵을 확인할 필요가 없습니다. 사실 이와 같은 데이터 저장소를 실제로 구현하려면 더 많은 사항을 고려해야 합니다. 실제 구현에서는 다음과 같은 사항을 고려해야 합니다.
- 파일 포맷
- 앞선 예에서와 같이 CSV는 로그에 적합한 파일 포맷이 아닙니다. 먼저 문자열의 길이를 바이트 단위로 인코딩한 다음 원시 문자열이 오는 바이너리 포맷이 더 빠르고 간단합니다.
- 레코드 삭제
- 키와 값을 삭제하려면 특수한 삭제 레코드(툼스톤이라고 불리는)를 추가해야 합니다. 세그먼트가 병합될 때 툼스톤은 병합 과정에서 삭제된 키의 이전 값을 무시합니다.
- 고장 복구
- 데이터베이스가 재시작되면 인메모리 해시 맵은 손실됩니다. 원칙적으로는 전체 세그먼트 파일을 처음부터 끝까지 읽고 각 키에 대한 최신 값의 오프셋을 확인해서 해시 맵을 복원할 수 있습니다. 그러나 이 방법은 세그먼트 파일이 크면 해시 맵 복원이 오래 걸리는 문제가 있습니다. 해시 맵을 조금 더 빠르게 로딩할 수 있게 snapshot을 디스크에 저장해두고 로딩 속도를 높일 수 있습니다.
- 덜 쓰여진 레코드
- 로그에 레코드를 추가하는 도중에 데이터베이스는 장애가 발생할 수 있습니다. 이러한 문제는 파일의 체크섬을 포함하여 로그의 손상된 부분을 탐지하고 이를 무시할 수 있습니다.
- 동시성 제어
- 쓰기를 엄격하게 순차적으로 로그에 추가하는 일반적인 방법은 하나의 쓰기 쓰레드만 사용하는 것입니다. 세그먼트는 append-only이거나 immutable이므로, 멀티 스레드에서 동시 읽기가 가능합니다.
지금까지 살펴본 append-only 로그는 언뜻 보면 낭비처럼 보입니다. 이전 값을 새로운 값으로 덮어써서 파일을 갱신하는 방법이 더 효율적인 것같이 보입니다. 그러나 append-only는 여러 이유에서 좋은 설계라고 볼 수 있습니다. 그 예는 다음과 같습니다.
- 추가와 세그먼트 병합은 순차적인 쓰기 작업이기 때문에 random write보다 훨씬 빠릅니다.
- 세그먼트 파일이 append-only나 immutable하면 동시성 처리와 고장 복구가 훨씬 간단해집니다. 예를 들어 값을 덮어쓰는 동안 데이터베이스가 죽는 경우에 대해 걱정할 필요가 없습니다. 왜냐하면 장애 복구시 이전 값과 새로운 값을 따로 쓰기 때문에 새로운 값을 쓰다가 데이터베이스가 죽더라도 이전 값을 이용하여 복구할 수 있습니다.
- 세그먼트 병합은 파편화되는 데이터 파일의 문제를 피할 수 있습니다.
그러나 이전에 사용한 색인 방법인 해시 테이블 색인의 경우 제한사항이 있습니다. 그 제한사항은 다음과 같습니다.
- 해시 테이블은 메모리에 저장해야 하므로 키가 너무 많은 경우 문제가 발생합니다.
- 해시 테이블의 경우 range query에 효율적이지 않습니다.
지금까지 가장 간단한 쉘 기반의 가장 간단한 저장소를 시작으로 로그 기반의 데이터 저장과 이를 효율적으로 읽을 수 있는 해시 색인에 관해 살펴 보았습니다. 다음 포스트는 이어서 해시 테이블 색인의 제한사항을 갖지 않는 색인 구조를 살펴볼 예정입니다.