저장소(Storage)와 검색(Retrieval) - 2
이전 포스트에 이어서 저장소와 검색을 계속 살펴보겠습니다. 이전 포스트 마지막 부분에 대한 설명은 해시 테이블을 통한 색인이 가진 제한사항에 대해 살펴보았습니다. 이러한 제한이 없는 색인 구조를 이어서 살펴보도록 하겠습니다.
SS 테이블과 LSM 트리

위 그림과 같이 log-structured 저장소 세그먼트는 key-value 쌍의 시퀀스입니다. key-value 쌍은 쓰여진 순서대로 저장되며 로그에서 같은 키를 갖는 값 중 나중 값이 최신 값이 됩니다. 여기에 간단한 변경사항을 적용해 봅시다. 세그먼트를 key를 기준으로 정렬하는 것입니다. 일단 이러한 변경은 순차적으로 쓰는 것을 못하게 할 것 같습니다. 그러나 이러한 문제는 조금 더 뒤에 살펴보도록 하겠습니다. 먼저 세그먼트를 정렬하는거에 집중해봅시다.
이와 같이 세그먼트를 키로 정렬한 포맷을 SS 테이블(Stored String Table)이라고 합니다. 그리고 컴팩션을 통해 병합된 세그먼트 파일에는 키가 하나만 나타나야합니다. SS 테이블은 해시 색인을 가진 로그 세그먼트에 비해 큰 장점을 가집니다.
- 세그먼트 병합이 간단하고 효율적입니다. 이러한 접근 방식은 병합정렬(mergesort) 알고리즘과 유사합니다. 세그먼트를 병합하여 만든 새로운 파일도 키로 정렬되어 있습니다. 병합 중 같은 키를 가지고 있는 경우 가장 최근 세그먼트 값을 사용합니다.
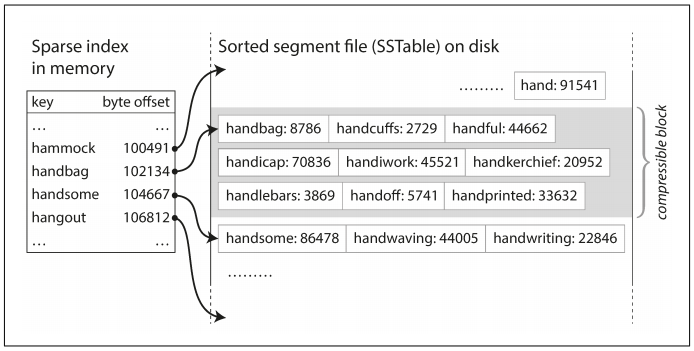
- 세그먼트는 정렬되어 있기 때문에 특정 키를 찾기 위해 모든 키를 색인으로 유지할 필요가 없습니다. 아래의 그림에서 처럼 찾으려는 키가 handiwork이고 할 때 해당 키가 색인이 되어 있지 않더라도 handbag과 handsome의 키 오프셋을 알고 있기 때문에 그 사이에 있는 걸 미리 알 수 있습니다. 단, handbag과 handsome을 스캔하더라도 키가 파일에 존재하지 않는 경우 찾지 못합니다. 그리고 일부 키에 대한 오프셋을 알려주는 인메모리 색인이 여전히 필요로 합니다. 그러나 모든 키가 색인되어 있지 않고 드문 드문 색인이 되어 있어서 sparse index라고 합니다.
- 읽기 요청은 여러 key-value 쌍을 요청 범위 내에서 스캔하기 때문에 해당 레코드들을 블록으로 그룹화를 하고 파일에 쓰기전에 압축을 하여 디스크 공간을 절약하고 I/O 사용 대역폭도 줄입니다. 아래의 그림에서 회색 부분이 하나의 블록을 나타냅니다.
SS 테이블과 생성 유지
앞서 SS테이블을 만드려면 순차 쓰기를 하지 못할 것 같다고 이야기 했습니다. 순차 쓰기의 장점을 얻을 수 없게 되는 문제가 발생하게 되죠. 쓰기는 랜덤하게 발생하기 때문에 정렬된 구조를 유지하는 방법이 필요합니다. 쓰기가 발생할때 바로 디스크 상에 정렬되도록 쓰는 방법도 있겠지만 메모리 상에서 정렬된 구조를 유지하는게 훨씬 간단합니다. 이렇게 데이터가 들어올 때마다 정렬된 순서로 자료를 유지하는 대표적인 자료구조는 레드 블랙 트리나 AVL 트리가 있습니다. 이러한 자료구조를 이용하면 순서에 상관없이 키를 삽입해도 정렬된 순서로 키를 읽어올 수 있습니다.
지금까지 고려한 것을 토대로 저장소 엔진은 다음과 같이 만들 수 있습니다.
- 쓰기 요청이 들어오면 인메모리 banlanced tree 자료구조에 데이터를 추가합니다. 보통 이러한 인메모리 트리를 멤테이블(memtable)이라고도 합니다.
- 멤테이블이 수 메가바이트 정도로 쌓여서 임계값보다 커지면 SS테이블 파일로 디스크에 기록합니다. 여기서 임계값을 세그먼트의 크기입니다. 이미 트리가 키로 정렬되어 key-value 쌍을 유지하고 있기 때문에 효율적으로 디스크에 쓸 수 있습니다. 새로운 SS 테이블은 가장 최신 세그먼트가 됩니다. 디스크에 SS 테이블이 쓰여지는 동안 새로운 멤테이블에 쓰기도 가능합니다.
- 읽기 요청이 들어오면 제일 먼저 멤테이블에 키가 존재하는지 찾습니다. 만일 존재하지 않으면 최근 세그먼트부터 차례대로 키를 찾을 때 까지 반복합니다.
- 백그라운드에서 이따금 세그먼트 파일을 합치고 삭제 표시가 있는 값을 삭제하는 병합과 컴팩션 프로세스를 수행합니다.
여기에는 한가지 문제가 있습니다. 바로 데이터베이스에 장애가 발생하여 죽는 경우 디스크로 기록되지 않은 멤테이블의 데이터가 손실되는 문제입니다. 이러한 문제를 해결하기 위해서 멤테이블의 값을 복원하기 위한 로그를 따로 두어야 합니다. 그래서 매번 쓰기가 발생할 때마다 디스크에 데이터를 유지합니다. 이 경우 디스크 상에 순서를 유지할 필요는 없습니다. 단지 멤테이블을 복구하는 용도로만 사용하기 때문입니다. 또한 크기도 멤테이블 사이즈 정도 밖에 안되기 때문에 크게 문제가 되지 않습니다. 그리고 SS 테이블에 기록되면 해당 로그는 삭제할 수 있습니다.
SS 테이블에서 LSM 트리 만들기
여기에서 사용되는 색인 구조는 화 병합 트리(Log-Structured Merge-Tree) 또는 LSM 트리라고 합니다. 정렬된 파일의 병합과 컴팩션의 원리를 기반으로 하는 저장소 엔진을 LSM 저장소 엔진이라고 부릅니다.
지금까지 기술된 알고리즘은 기본적으로 LevelDB와 RocksDB에서 사용합니다. 또한 구글의 빅테이블 논문에서 영감을 얻은 카산드라와 HBase에서도 유사한 저장소 엔진을 사용합니다.
성능 최적화
LSM 트리 알고리즘은 데이터베이스에 존재하지 않는 키를 찾는 경우 느릴 수 있습니다. 멤테이블부터 시작해서 가장 오래된 세그먼트까지 거슬러 올라가서 확인해야 하기 때문입니다. 이렇게 존재하지 않는 키에 대한 접근을 최적화하기 위해서 저장소 엔진은 보통 블룸 필터(Bloom filter)를 사용합니다. 블룸 필터는 키가 데이터베이스에 존재하지 않음을 알려주므로 존재하지 않는 키를 위한 불필요한 디스크 읽기를 방지할 수 있습니다. 여기서는 블룸 필터에 대한 원리에 대해서는 설명하지 않고 있습니다. 블룸 필터에 대한 설명은 이 슬라이드를 보시면 도움이 되실겁니다.
다음으로 SS 테이블을 압축하고 병합하는 순서와 시기를 결정하는 다양한 전략이 존재합니다. 일반적으로 size-tiered와 leveled compaction 2가지 있습니다. LevelDB와 RocksDb는 leveled compaction을 Hbase는 size-tiered compaction을 카산드라는 둘다 지원합니다. 해당 전략에 대해서 간략히 살펴보면 size-tiered compaction은 새롭고 작은 SS테이블을 오래된 큰 SS테이블에 병합합니다. leveled compaction은 키 범위를 더 작은 SS테이블로 나누고 오래된 데이터는 분리된 레벨로 이동시켜서 컴팩션을 점진적으로 진행시켜 디스크 공간을 덜 사용합니다. 해당 전략을 조금 더 자세히 살펴보고 싶은 분은 다음 사이트를 참고하시기 바랍니다.
LSM 트리의 기본 개념은 백그라운드에서 SS 테이블을 지속적으로 병합하는 것입니다. 데이터가 정렬된 순서로 저장된다면 range query를 효율적으로 실행할 수 있습니다. 또한 디스크 쓰기가 순차적이기 때문에 LSM 트리는 매우 높은 쓰기 처리량을 보장할 수 있습니다.
이번 포스트는 SS테이블과 LSM 트리에 관해 살펴보았습니다. 해시 테이블을 사용한 색인의 제한사항을 이전 포스트에서 살펴보았고 이번 포스트에서는 이런 제한이 없는 색인 구조에 대해 살펴보았습니다.
다음 포스트는 이어서 데이터베이스에서 가장 일반적인 색인 유형인 B 트리에 대해 살펴보겠습니다.
References
- https://notes.shichao.io/dda/ch3/
- https://www.slideshare.net/charsyam2/bloomfilter-82589241
- https://charsyam.wordpress.com/2012/09/05/발-번역-leveled-compaction-in-apache-cassandra/