저장소(Storage)와 검색(Retrieval) - 3
이전 포스트에 이어서 세 번째 포스트입니다. 이전 포스트에서는 SS테이블과 LSM 트리에 관해 알아보았습니다. 이번 포스트에서는 데이터베이스에서 가장 많이 사용하고 일반적인 색인 유형인 B 트리에 대해서 살펴보겠습니다.
B 트리
B 트리는 거의 대부분의 관계형 데이터베이스에서 표준 색인 구현으로 사용할 뿐만 아니라 비관계형 데이터에서도 사용합니다. B트리는 SS테이블과 같이 키로 정렬된 key-value 쌍을 유지하지 때문에 key-value 검색과 range query에 효율적입니다. 이와 같이 LSM 트리와는 유사한 점은 이게 다이고 B 트리의 설계 철학은 매우 다릅니다.
LSM 트리는 일반적으로 수 메가바이트 이상의 가변 크기를 가진 세그먼트를 나누고 순차적으로 세그먼트를 기록합니다. 반면 B 트리는 전통적으로 4KB 크기의 고정 크기 블록이나 페이지로 나누고 한번에 하나의 페이지에 읽기 또는 쓰기를 합니다. 이와 같이 고정 크기 블록을 사용하는 이유는 디스크가 고정 크기 블록으로 배열되어 있기 때문입니다. 즉 하드웨어와의 관련성 때문입니다.
다음 그림은 B 트리를 이용한 키를 검색하는 방법을 나타내는 그림입니다.
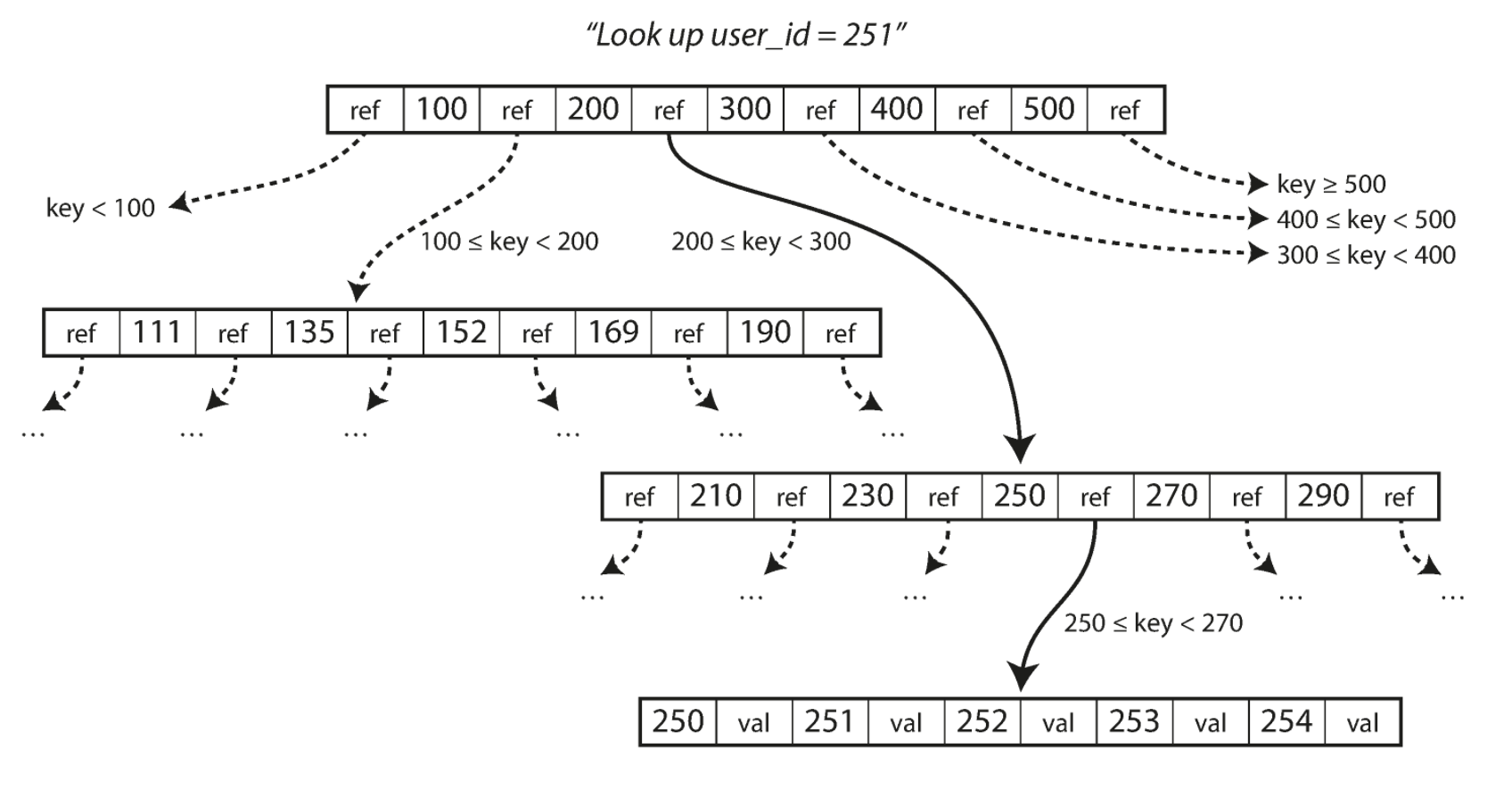
색인에서 원하는 키를 찾으려면 루트에서부터 시작합니다. 위의 그림은 user_id 251을 찾고 있기 때문에 200과 300 사이의 페이지의 참조를 따라갑니다. 그 다음 250과 270 사이에 참조를 따라가서 최종적으로 leaf 페이지에 도달하고 252의 값을 찾습니다.
B 트리의 하나의 페이지에서 하위 페이지를 참조하는 수를 분기 계수(branching factor)라고 합니다. 위의 그림에서는 분기 계수가 6입니다. 실제로 분기 계수는 보통 수백 개에 달합니다.
B 트리에 존재하는 키의 값을 update 하려면 리프 페이지까지 검색한 후에 페이지에 있는 값을 변경 후 디스크에 다시 씁니다. 새로운 키를 추가하려면 아래의 그림과 같이 새로운 키를 포함하는 범위의 페이지를 찾아 해당 페이지에 키와 값을 추가합니다. 만일 쓰려고 하는 페이지에 여유 공간이 없으면 페이지를 둘로 나누고 상위 페이지가 새로운 키 범위를 가진 하위 페이지들을 알 수 있게 갱신한 후 추가합니다.
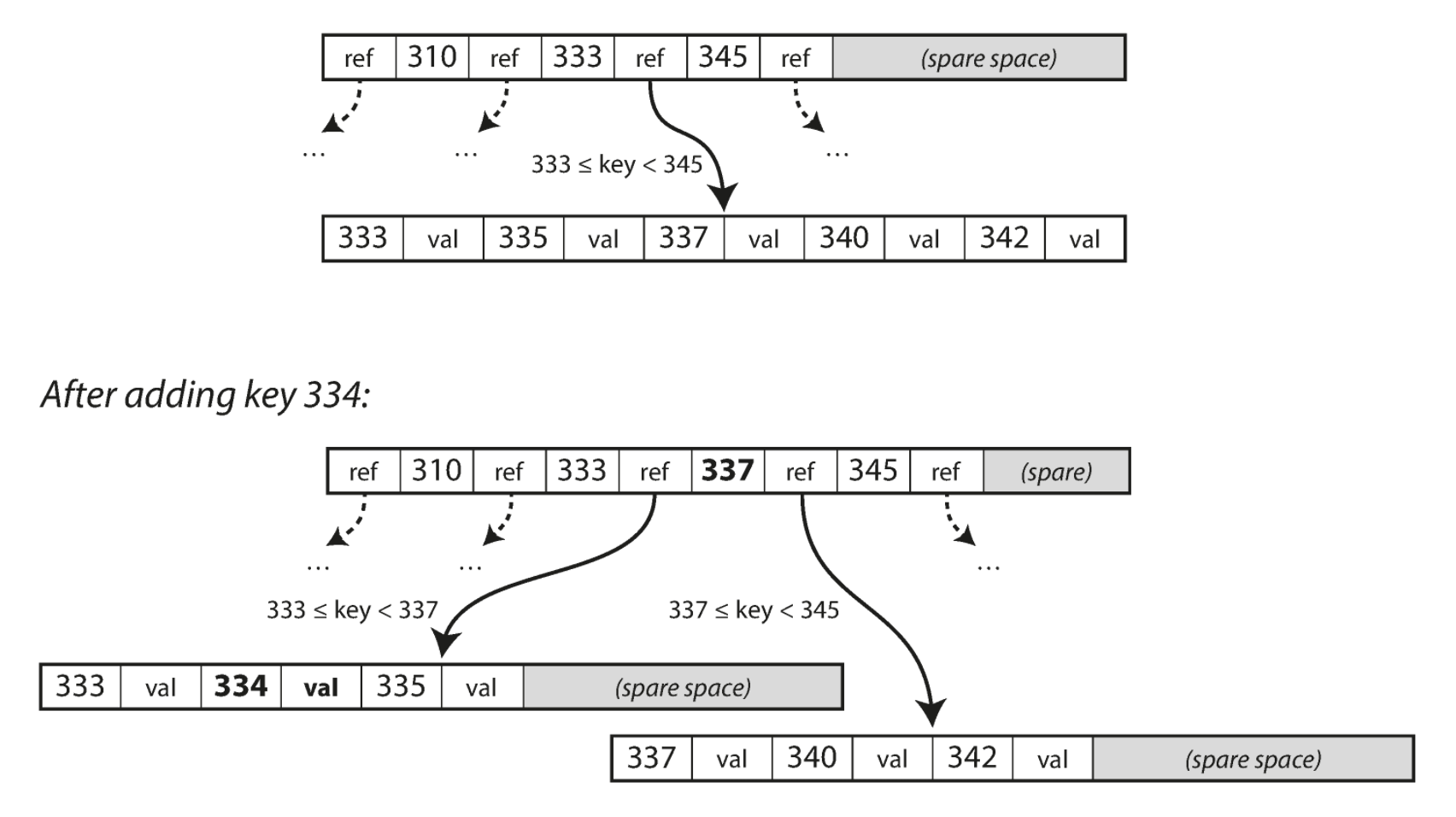
이 알고리즘은 트리가 계속 균형을 유지하는 것을 보장합니다. 대부분의 데이터베이스는 B 트리의 깊이가 4단계 정도면 충분하므로 검색하려는 페이지를 찾기 위해 많은 페이지 참조를 따라가지 않아도 됩니다. 분기 계수가 500이고 페이지 크기가 4KB이면서 깊이가 4단계인 트리는 256TB(500^4 * 4096 = 256TB)까지 저장할 수 있습니다.
신뢰할 수 있는 B 트리 만들기
B 트리의 기본적인 쓰기 동작은 새로운 데이터를 디스크에 덮어쓰는 것입니다. 그러나 삽입 때문에 페이지가 너무 많아져 페이지를 나눠야 한다면 분할된 두 페이지를 기록하고 두 하위 페이지의 참조를 갱신하도록 상위 페이지를 덮어써야 합니다. 만일 일부 페이지만 기록하고 데이터베이스에 장애가 발생한다면 색인이 훼손됩니다. 이렇게 색인이 훼손되면 고아 페이지(orphan page)가 발생할 수 있습니다. 고아 페이지란 어떤 페이지와도 부모 관계가 없는 페이지를 이야기합니다.
이렇게 데이터베이스의 장애가 발생한 상황에서도 스스로 복구할 수 있도록 하기 위해서 일반적으로 디스크에 write-ahead log(WAL)라고 하는 데이터 구조를 추가해 B 트리를 구현합니다. WAL은 트리 페이지에 변경된 내용을 적용하기 전에 모든 B 트리의 변경사항을 기록하는 append-only 파일입니다. 이 로그를 통해 데이터베이스 장애 이후 복구될 때 일관성있는 상태로 B 트리를 다시 복원합니다.
또한 다중 스레드가 동시에 B 트리에 접근한다면 주의 깊게 동시성 제어를 해야 합니다. 그렇지 않다면 스레드가 일관성이 깨진 상태의 트리에 접근할 수도 있기 때문입니다. 동시성 제어는 보통 latch(가벼운 잠금(lock))으로 트리 데이터 구조를 보호합니다.
B 트리와 LSM 트리 비교
경험적으로 LSM 트리는 보통 쓰기에서 더 빠른 반면 B 트리는 읽기에서 더 빠릅니다. LSM 트리가 읽기가 더 느린 이유는 각 컴팩션 단계에 여러 데이터 구조와 SS 테이블을 확인해야 하기 때문입니다.
LSM 트리의 장단점
데이터베이스에 쓰기 한 번이 디스크에 여러번 쓰는 효과를 write amplification이라고 합니다. 상대적으로 LSM 트리가 상대적으로 쓰기 증폭이 B 트리보다 낮고 트리에서 여러 페이지를 덮어 쓰는 것이 아닌 순차적으로 컴팩션된 SS 테이블 파일을 쓰기 때문에 더 높은 쓰기 처리량을 유지할 수 있습니다. 또한 압축률이 더 좋습니다.
단점으로는 컴팩션 과정으로 인해 읽기와 쓰기 성능에 영향을 줄 수 있다는 점입니다. 쓰기 처리량이 높아도 디스크의 쓰기 대역폭은 유한하기 때문입니다. 또한 B 트리의 경우 각 키가 색인의 한 곳에만 정확히 존재하지만 로그 구조화 저장소 엔진은 다른 세그먼트에 같은 키를 가지는 여러 복사본이 존재할 수 있습니다. 이러한 이유 때문에 강력한 트랜잭션을 제공하는 데이터베이스에는 B 트리가 매력적입니다.
이번 포스트에서는 B 트리를 통한 색인 방법과 B트리와 LSM 트리를 비교하여 살펴보았습니다. 다음 포스트에서는 이어서 온라인 트랜잭션 처리(OLTP)와 온라인 분석 처리(OLAP)을 비교하여 살펴볼 예정입니다.