스트리밍의 첫걸음 - 데이터 스트리밍 처리의 개념 정리
스트리밍 처리의 중요성이 점점 중요해지고 있습니다. Apache Spark Streaming부터 새로운 스트림 처리의 강자인 Apache Flink와 같은 스트리밍 처리 엔진 등의 사용 사례가 많아지고 있습니다. 그래서 이번 기회에 스트리밍 처리에 대한 기본 개념들에 대해 정리해보고자 합니다.
스트리밍의 정의는 무엇일까요? 스트리밍은 다양한 의미가 있을 수 있습니다. 그러나 데이터 처리의 관점에서 보았을 때 Streaming 101에 나와있는 문구가 잘 정의되어 있는 것 같습니다.
a type of data processing engine that is designed with infinite data sets in mind.
위의 정의된 대로 “무한의 데이터 셋을 염두에 두고 설계된 데이터 처리 엔진의 유형"이라고 생각됩니다. 앞으로 “스트리밍"이라는 용어를 사용할 때는 Unbounded data를 처리하기 위해 설계된 실행 엔진을 의미합니다. 그럼 이제 이 스트리밍 처리에서 사용되는 기본 용어들에 관해 살펴보도록 하겠습니다.
Unbounded data vs Bounded data
- Unbounded data
- 데이터가 끊임없이 계속 생성되는 무한의 데이터 셋
- 스트리밍 데이터라고 함
- Bounded data
- 유한한 데이터 셋이며 “배치” 데이터라고 함
Event time vs Processing time
데이터 처리 시스템에서는 일반적으로 대표적인 두가지 시간이 있습니다. 바로 이벤트 시간과 처리 시간입니다. 이번 포스트에서는 이벤트 시간과 처리 시간에 관해서는 간단히 설명하겠습니다. 이벤트 타임과 처리 시간과 관련해서는 본 블로그에 이벤트 시간 처리와 워터마크에서 상세히 설명하고 있습니다.
- Event time
- 이벤트가 실제로 발생한 시간
- Processing time
- 시스템에서 이벤트를 처리한 시간
이상적인 경우에 이벤트 시간과 처리 시간이 동시에 처리됩니다. 그러나 일반적으로 다양한 요소들에 의해서 두 시간 사이에 차이가 발생합니다. 다음 그림은 이벤트 시간과 처리 시간의 관계를 나타내는 그래프입니다.

실제 처리 되는 시간의 경우 이상적인 경우와 차이가 나는 것을 볼 수 있습니다. 주로 이벤트 시간과 처리 시간의 차이를 skew라고 표현합니다. 이렇게 skew 발생하는 원인들은 네트워크 지연과 관련된 이슈나 실행 엔진, 하드웨어 이슈, 분산 시스템 로직 문제 등 굉장히 다양합니다.
데이터 처리 패턴
Bounded data processing
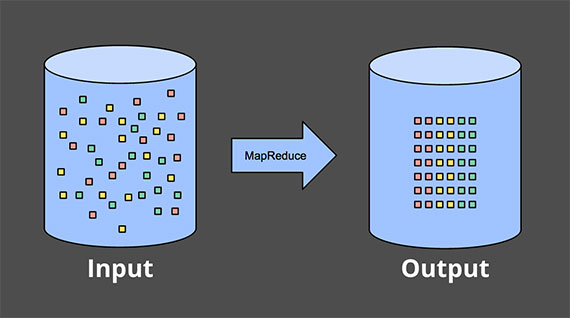
Bounded data processing은 우리가 흔히 알고 있는 MapReduce와 같은 데이터 처리 엔진을 통해 데이터를 처리하고 정제된 데이터 셋을 만드는 것입니다. 제한된 데이터를 전부 읽어서 처리하는 것입니다.
Unbounded data processing
Unbounded data processing의 경우 Batch와 Streaming 2가지 방식으로 처리합니다.
Batch
배치에서 Unbounded data를 처리하는 경우 데이터를 배치 처리에 적합하게 데이터를 분할해야 합니다. 데이터를 분할하는 방법은 다음과 같이 2가지 방법이 있습니다.
- Fixed window
- 배치 처리에서 일반적으로 사용되는 방법으로 고정된 크기의 window로 나누고 각 window를 bounded data 소스로 처리하는 것입니다.

- Sessions
- 세션은 일반적으로 특정 사용자의 활동 기간과 같은 것을 나타냅니다. 주로 사용자가 일정 시간 이상 활동을 하지 않는 경우 데이터를 분할합니다.
- 배치에서 세션 기반으로 처리하는 경우에는 그림과 같이 특정 사용자 세션이 잘리는 문제가 발생합니다. 뒤에서 스트리밍에서 세션 처리를 어떻게 하는지 살펴보겠습니다.

Streaming
Unbounded data는 배치 처리와 다르게 스트리밍 처리에서 더 잘 처리할 수 있습니다. 스트리밍 처리에서 데이터를 처리하는 방법은 다음과 같습니다.
-
Time-agnostic
- 일반적으로 시간에 구애 받지 않는 데이터를 처리하는 것입니다. 즉, 시간과 상관 없이 처리되는 데이터입니다. 그렇기 때문에 데이터가 들어오는대로 처리하면 됩니다.
-
Filtering
- time-agnostic 처리의 가장 기본적인 형태입니다. 필터링은 들어오는 데이터 중 특정 데이터만 필터링해서 처리하는 구조입니다.
- Inner-joins
- time-agnostic 처리 방법응 또 다른 예입니다. 두 개의 unbounded data 소스에서 일치하는 값이 있으면 조인이 됩니다.
- 두 소스로 부터 일치하는 데이터가 언제 도착할지 모르기 때문에 버퍼가 필요로 하고, 조인이 된 결과를 버퍼에서 삭제하도록 해야 합니다. 또한 한쪽의 소스의 데이터가 도착하지 않을 수 있기 때문에 버퍼를 삭제하는 정책이 필요로 합니다.

- Approximation algorithms(근사 알고리즘)
- 근사 알고리즘은 대략적인 데이터의 근사값만을 구하는 알고리즘입니다. 이 방식은 실시간 데이터 분석에서 많이 사용됩니다. 전체 데이터를 분석하지 않고 일부만 분석하거나 대략적인 데이터의 근사값만을 구하여 빠르게 결과를 보여줍니다. 이러한 근사 알고리즘은 시간 정보에 구애 받지 않고 처리됩니다.
- 대표적인 근사 알고리즘은 approximate Top-N, K-means와 같은 것들이 있습니다.
-
Windowing
- 윈도우는 데이터 소스로부터 처리를 위해 시간에 따라 경계를 나누고 유한한 청크로 분할하는 개념입니다. 스트리밍 처리에서 중요한 개념입니다. 다음 그림은 세가지 다른 windowing 패턴을 보여줍니다.
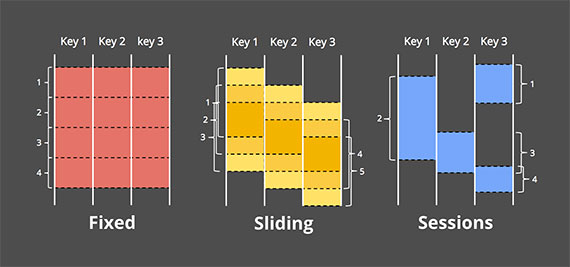
- Fixed windows
- Fixed windows는 고정된 크기의 시간으로 분할하는 방식입니다. 위의 그림에서 처럼 고정된 시간으로 분할하되 겹치지는 않습니다.
- Sliding windows
- Fixed windows와 같이 고정된 길이로 분할이 됩니다. Fixed window랑 다른 점은 바로 기간인데 이 기간이 길이보다 작으면 윈도우가 겹치게 됩니다. 그리고 기간과 길이가 같으면 Fixed windows와 같습니다. 즉 고정된 윈도우 크기가 설정되고 윈도우가 사용자가 정한 기간 후에 이동하는 것입니다.
- Sessions
- 세션 윈도우는 사용자가 활동을 시작해서 일정 시간 동안 사용자가 행동을 하지 않을 때까지(이벤트가 발생하지 않을 때까지)를 하나의 세션으로 묶어 처리하는 방법입니다. 자료 사용자의 행동을 분석하는데 많이 사용합니다.
시간에 따른 윈도우 처리 방법
-
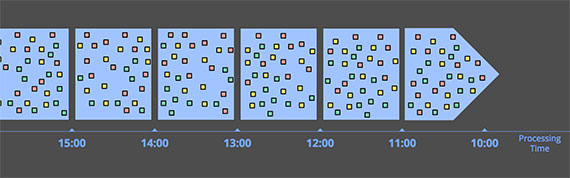
처리 시간(Processing time)에 따른 윈도우 처리
- 처리 시간을 기준으로 처리하는 경우에는 간단합니다. 스트림 처리 엔진에서 윈도우를 만들 때 일정 처리 시간이 경과할 때까지(윈도우 크기 만큼) 들어오는 데이터를 윈도우에 버퍼링을 한 다음에 처리합니다. 이 방법은 굉장히 심플합니다. 또한 지연된 데이터를 처리하는 것을 고민할 필요가 없습니다. 이런 방식은 주로 관찰하는 소스의 데이터를 기반으로 특정 정보를 추론할 떄 많이 사용합니다. 다양한 모니터링 시나리오가 이에 해당됩니다.
-
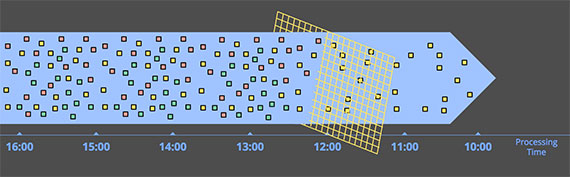
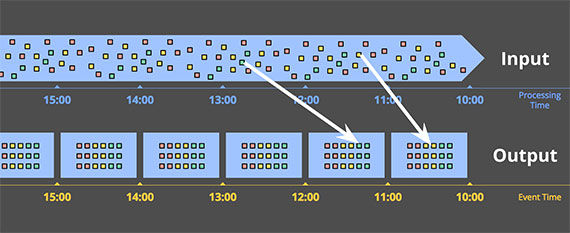
이벤트 시간(Event time)에 따른 윈도우 처리
- 이벤트 시간에 따른 윈도우 처리는 이벤트가 실제로 발생한 시간을 기준으로 윈도우를 만들어서 처리하는 것입니다. 이벤트 시간을 기준으로 처리하는 경우에 데이터가 순서대로 들어오지 않고 데이터 도착 시간이 지연될 수 있는 등의 예외 상황이 발생할 수 있습니다.
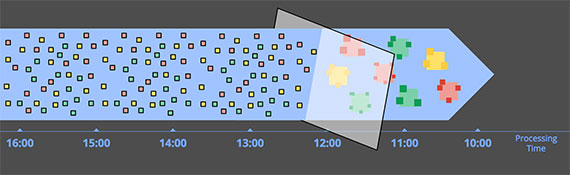
- 아래의 그림을 예를 들어보겠습니다. 왼쪽 화살표에 나와있는 데이터의 경우 처리 시스템에 도착한 시간이 12:00-13:00 사이지만 이벤트 시간은 11:00-12:00 사이의 데이터입니다. 이러한 경우 11:00-12:00의 윈도우에 데이터를 반영해줘야 합니다. 그럼 이러한 지연된 데이터를 반영해주는 방법과 고려사항은 어떤 것이 있을까요?
- 버퍼링(Buffering) : 지연된 데이터를 반영하기 위해서 윈도우의 수명을 더 늘려주는 방식입니다. 즉, 윈도우를 버퍼링해두는 것입니다.
- 완료(Completeness) : 버퍼링을 적용하는 경우 얼마나 버퍼링을 유지해야 할까요? 데이터의 지연을 언제까지 허용할 것인지 정해야 합니다. 버퍼가 모든 지연된 데이터를 처리할 정도로 크게 만드는 것은 현실적으로 어렵기 때문입니다. 그래서 데이터가 언제쯤 도착할 것인지 휴리스틱하게 처리하는 방법이 있습니다(예를 들어 워터마크와 같은 기법입니다).
정리
지금까지 스트리밍에서 사용되는 개념들에 대해 살펴보았습니다. 이벤트 시간과 처리 시간의 차이를 설명하고 데이터 별로 배치와 스트리밍의 차이를 알아보았습니다. 이번 포스트를 통해서 데이터 스트리밍 처리의 기본 개념에 대해 익히셨을 것이라 생각됩니다.