스트리밍 두 번째 걸음 - 배치를 넘어서
이전 포스트에서는 데이터를 Bounded data와 Unbounded 데이터 구별하고, 그것을 처리하는 방법에 관해 살펴보았습니다. Unbounded data를 처리할 때 이벤트 시간과 처리 시간의 차이점에 대해서 다뤘습니다. 또한 윈도우 개념도 함께 알아보았습니다. 이번 포스트에서는 워터마크, 트리거, 어큐뮬레이션에 관해 자세히 살펴보겠습니다.
- 워터마크(Watermark) : 워터마크는 이벤트 시간과 관련된 입력 데이터의 완료성을 나타내는 방법입니다. X라는 시간 값이 있는 워터마크의 의미는 “이벤트 시간이 X 이전의 모든 입력 데이터가 입력되었다"는 것을 의미합니다. 이와 같이 워터마크는 끝을 모르는 Unbounded data를 처리할 때 진행률 지표로 사용합니다.
- 트리거(Trigger) : 트리거는 윈도우 내용을 평가할 시점을 결정하는 메커니즘입니다. 트리거는 출력을 내보낼 시기를 선택할 때 유연성을 제공합니다.
- 어큐뮬레이션(Accumulation) : 어큐뮬레이션은 동일한 윈도우에서 확인할 수 있는 여러 결과의 관계를 지정하는 방법입니다. 즉, 윈도우마다 차이를 확인하거나 윈도우 별 누적 결과를 이야기하는 것입니다.
이제 이러한 개념들을 이해하기 위해서 예제를 통해 살펴보겠습니다. 오늘 자세히 살펴볼 워터마크와, 트리거, 어큐뮬레이션뿐만 아니라 앞서 살펴본 데이터를 변환하는 트랜스포메이션(Transformation)부터 윈도우 처리도 함께 예제를 통해 알아볼 예정입니다. 예제는 Apache Flink를 기반으로 살펴볼 예정이며, Apache Spark이나 Apache Beam를 사용하셨던 분들은 예제가 익숙할 것입니다.
Transformation
트랜스포메이션은 데이터를 원하는 형태로 가공하는 방법입니다. 트랜스포메이션하는 유형은 다음 그림과 여러 유형이 있습니다.
지금부터 예제를 통해 직접 살펴보겠습니다. input 데이터는 String이며, 팀 이름과 개인 별 점수가 탭(tab)으로 분리되어 있습니다.
val env = ExecutionEnvironment.getExecutionEnvironment
// get input data
val input = env.readTextFile("/path/to/file")
.map { l =>
val tokens = l.split("\t")
(tokens(0), tokens(1))
}
val scores = input
.groupBy(0)
.sum(1)
예제의 입력이 단일 키(하나의 팀)에 대해서 10개의 입력 데이터가 들어온 경우 다음과 같이 스코어의 총합은 51이 됩니다. 다음 그림의 x축은 이벤트 시간이며, y축은 처리 시간입니다.
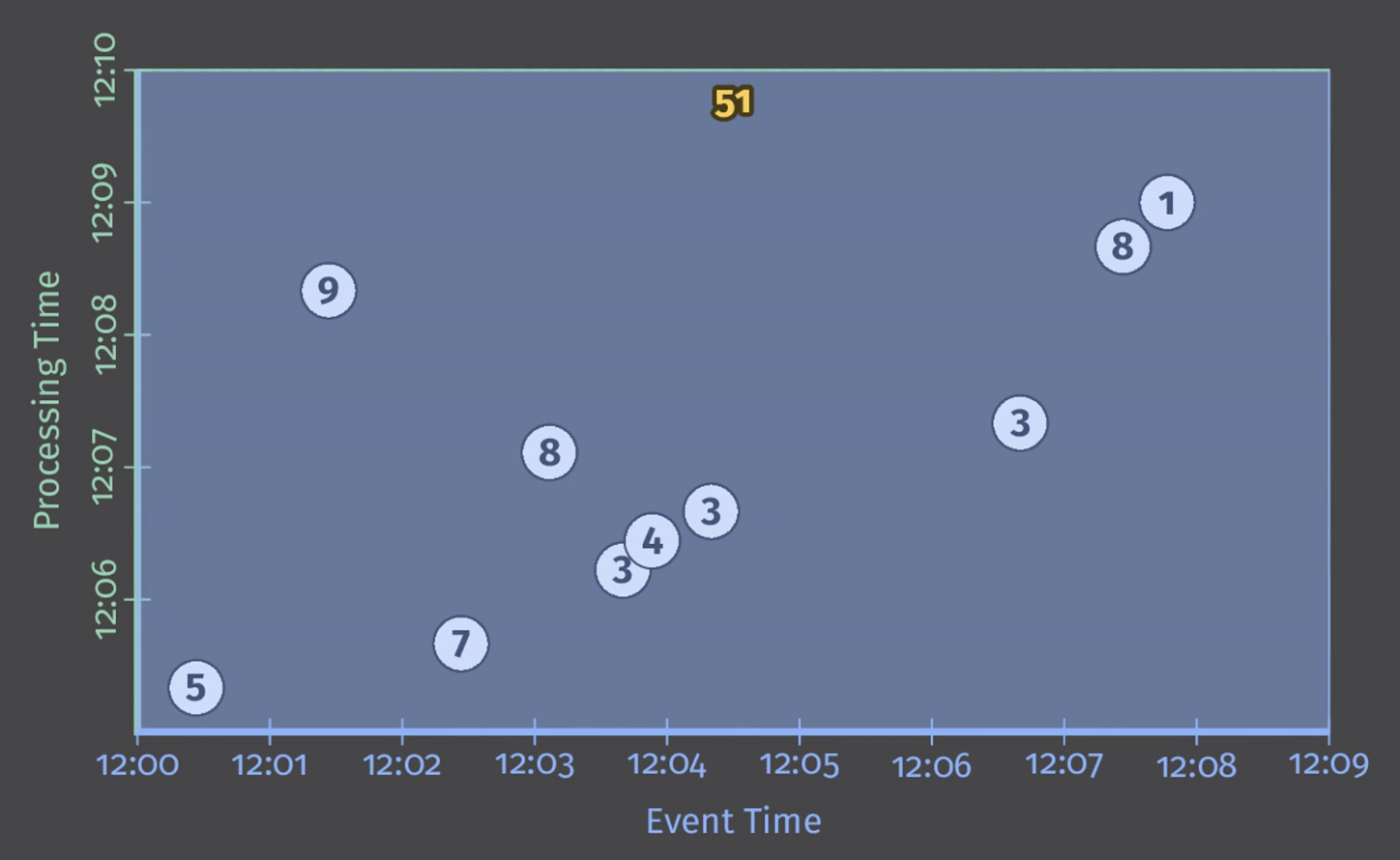
이번 예제에서는 배치 엔진에서 처리되는 것과 같이 처리됩니다. 특정 윈도우 트랜스포메이션을 적용하지 않았기 때문에 X축이 따로 나누어져 처리되지 않고 있습니다. 그러나 Unbounded data를 처리할 때 배치 처리로는 한계가 있습니다. 입력이 끝날 때까지 기다릴수 없는 것이죠. 그래서 이벤트 시간 계산은 어디서 이루어질 것인지 윈도우 설정을 통해 알아보겠습니다.
Windowing
윈도우는 시간적 경계에 따라 데이터 소스를 분할하여 처리하는 것입니다. 일반적으로 윈도우 전략은 다음 그림과 같이 Fixed(Tumbling), Sliding, Session 윈도우가 있습니다.
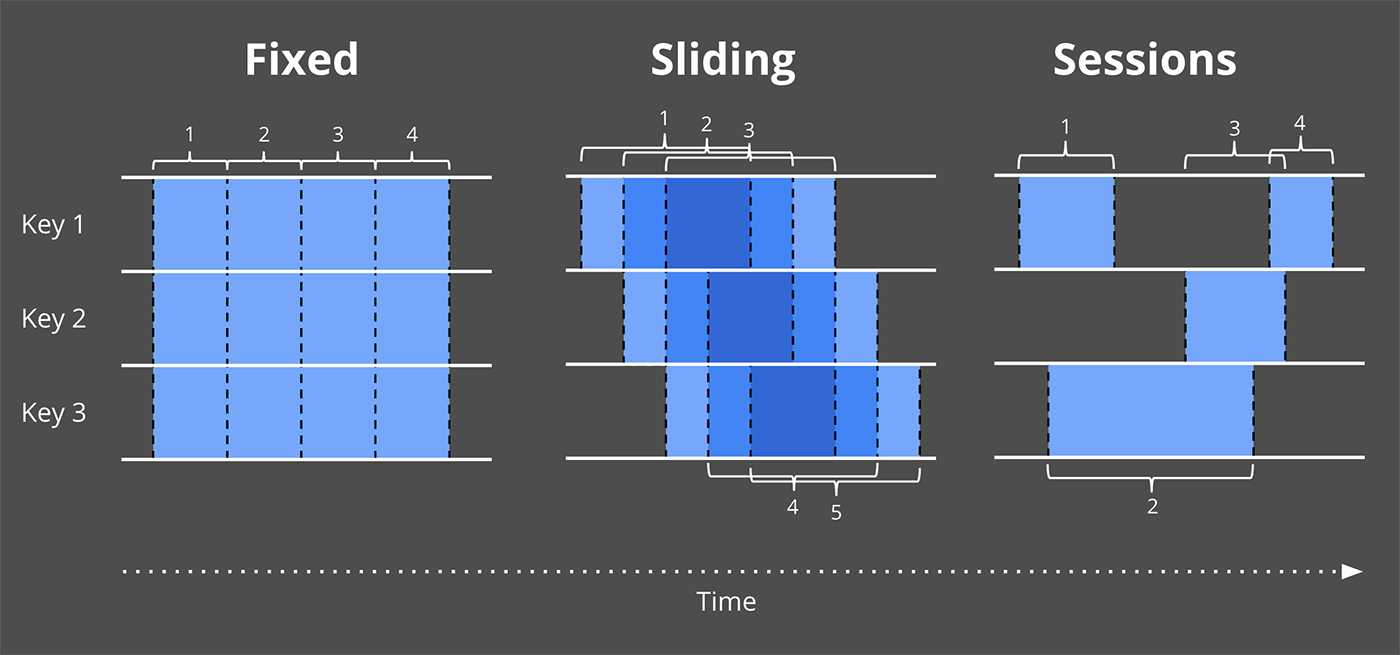
이제 코드로 사이즈가 2분인 Fixed window를 정의하는 방법은 다음과 같습니다.
val scoresByFixedWindow = input.keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(120))).sum(1)
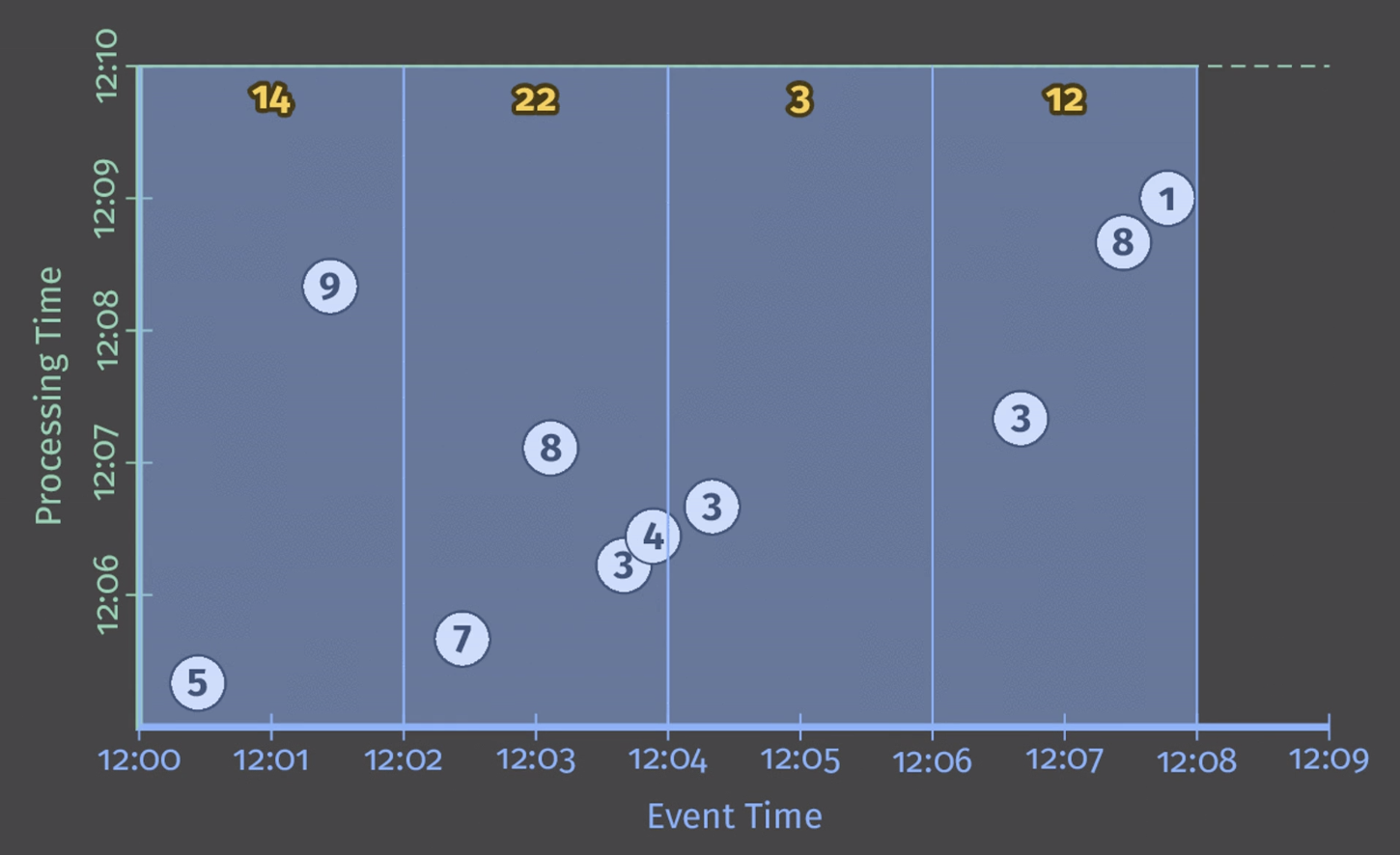
위의 그림과 같이 이벤트 타임을 기준으로 Fixed window 형태별로 결과가 나오는 것을 볼 수 있습니다. 지금까지 살펴본 2가지 예제는 배치 엔진에서 전체 데이터에 대한 배치 결과와 윈도우 파이프라인의 결과를 본 것입니다. 그러나 우리는 더 짧은 지연 시간을 가지며, Unbounded data를 처리하고 싶습니다. 그러면 스트리밍 엔진 사용으로 변경해야 합니다. 그러나 배치 엔진에서는 윈도우에 대한 입력이 완료되는 지점이 존재합니다. 여기서는 처리 시간인 12:10까지입니다. 그러나 Unbounded data를 처리하기 위해서는 완료 시점을 결정해야 하는데 이를 위해 워터마크를 사용합니다.
Watermark
워터마크는 어느 처리 시간 시점에 결과가 구체화될지 알려줍니다. 아래 그림의 빨간색 선은 본질적으로 워터마크를 의미합니다.
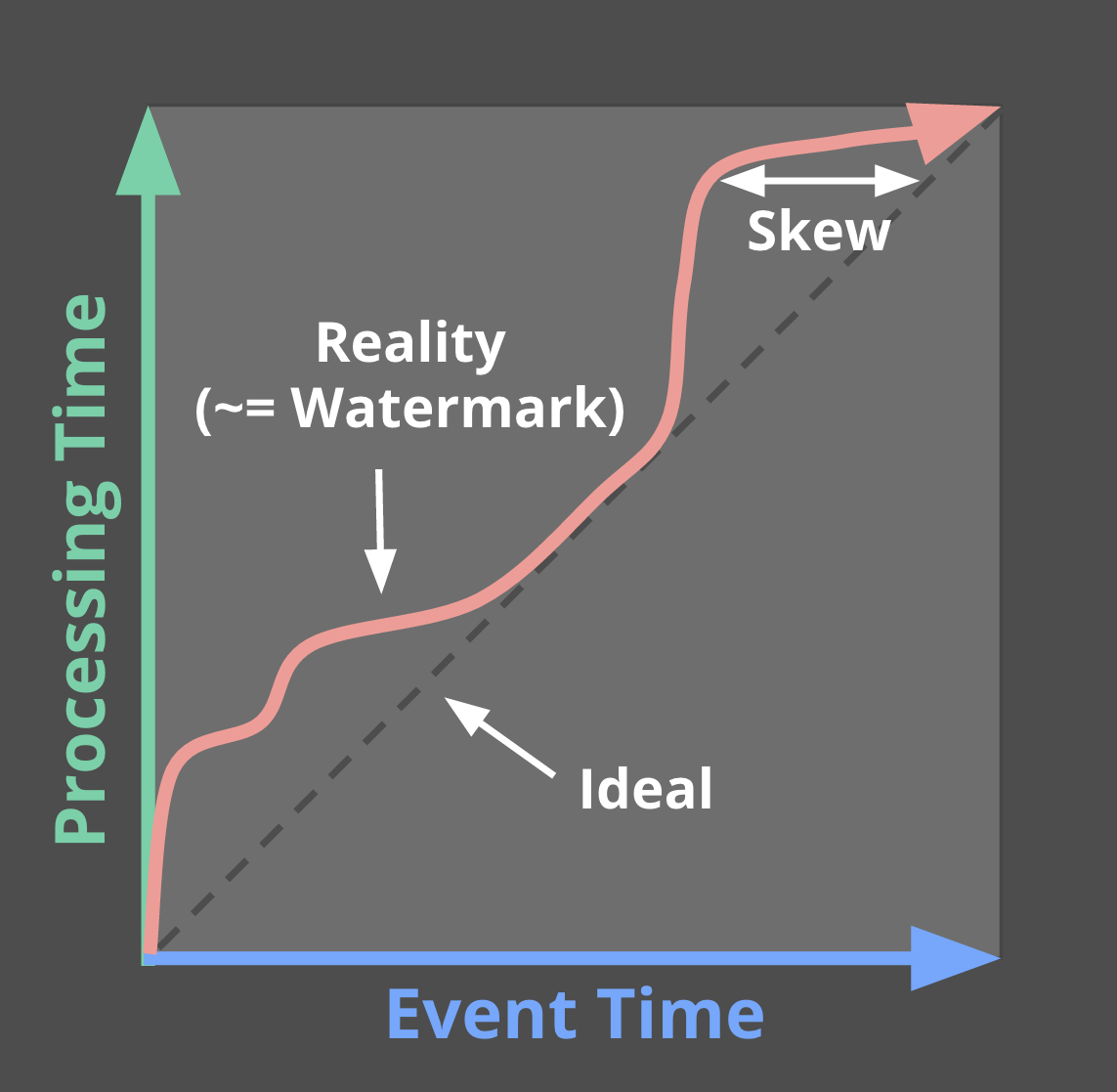
워터마크가 의미하는 것은 시스템이 워터마크를 기준으로 이벤트 시간이 워터마크보다 작은 모든 입력이 처리되었다고 알려주는 것입니다. 이러한 워터마크의 유형은 perfect와 heuristic 2가지가 있습니다.
- perfect 워터마크 : 모든 입력 데이터에 대해 완벽하게 아는 경우 perfect 워터마크를 사용합니다. 이 경우 지연된 데이터가 발생하지 않습니다.
- heuristic 워터마크 : 위와 같이 모든 입력 데이터를 완벽히 아는 것은 비현실적입니다. 그래서 휴리스틱 워터마크의 추정을 사용하여 인풋 데이터를 예측합니다. 너무 늦은 데이터는 버리는 것입니다.
다음 그림은 두가지 워터마크의 상태 변화를 보여주는 그림입니다.
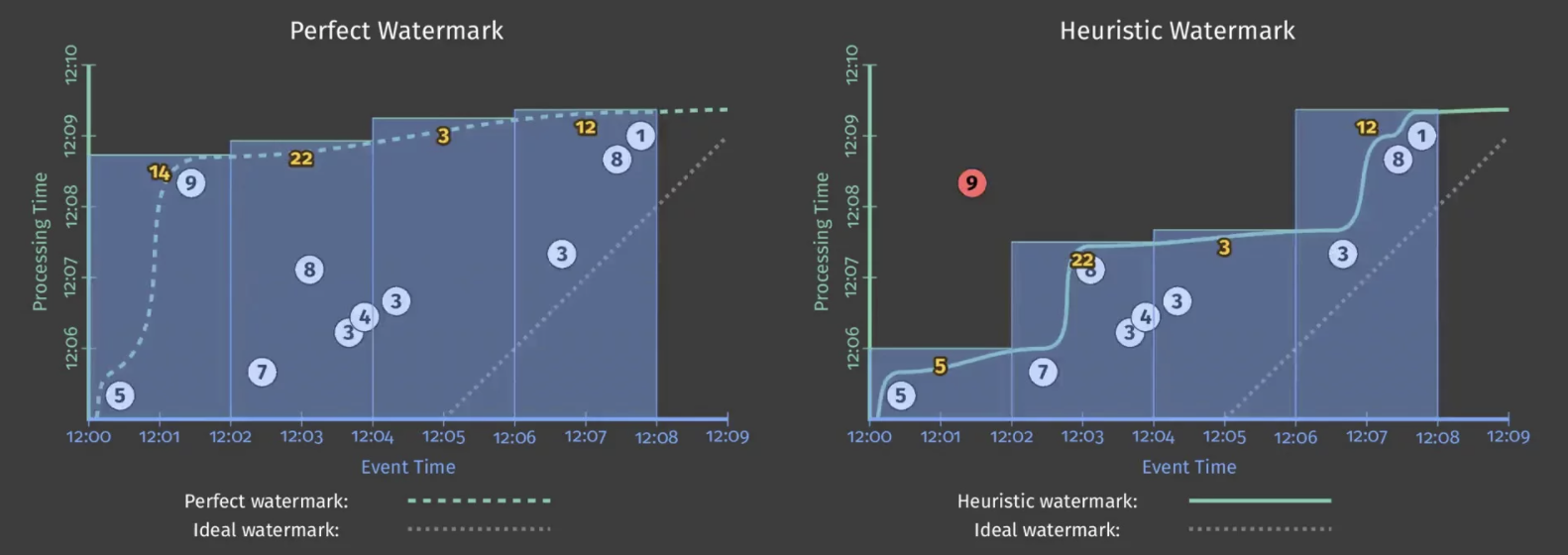
위 그림에서 휴리스틱 워터마크의 경우 스코어 9의 값을 고려하지 않아서 퍼펙트 워터마크와 모양이 다른 것을 알 수 있습니다. 왼쪽 그림의 경우 스코어 9로 인해 워터마크가 너무 느린 문제가 발생합니다. 그와는 다르게 오른쪽 그림에서는 워터마크가 빨라서 늦게 도착한 스코어 9를 합하지 않아서 잘못된 결과가 나오게 됩니다. 이렇게 워터마크가 너무 느리거나 워터마크가 너무 빠른 문제가 발생할 수 있습니다. 이와 같은 경우 짧은 지연 시간을 갖기 어렵거나 정확성을 갖지 못할 수 있습니다. 이러한 단점은 해결하는 방법이 바로 트리거(Trigger)입니다.
Trigger
트리거는 윈도우의 출력이 어느 처리 시간에 발생할 것인지 알려줍니다. 즉, 처리중인 데이터를 언제 다음 단계로 넘겨줄지(Tigger) 시스템에 알려줍니다. 예를 들어 윈도우가 종료되는 시간에 그 데이터를 다음 단계로 넘겨주는 것입니다. 이러한 트리거는 시간 기반 뿐만 아니라 다양한 종류를 제공합니다.
- Event time trigger : 이벤트 시간 기준으로 트리거를 합니다.
- Processing time trigger : 처리 시간을 기준으로 트리거를 합니다. 딜레이가 없이 진행되므로 정기적이고 주기적인 업데이트를 제공할 수 있습니다.
- Data-driven trigger : 데이터 기반 트리거는 데이터가 각 윈도우에 도착한 시점에 데이터를 데이터를 검사하여 지정한 조건이 충족되면 트리거되는 방식입니다. 예를 들어 윈도우에 일정 수의 데이터 요소가 수신되면 윈도우에서 결과를 내보내도록 처리합니다. 그래서 Element count trigger라고도 합니다.
- Punctuations : Punctuation은 “구두점"이라는 의미인데, 특정 데이터(이벤트)가 들어오는 순간에 트리거하는 방식입니다.
- Composite trigger(복합 트리거) : 트리거는 하나의 트리거 뿐만 아니라 여러 트리거를 조합해서 사용이 가능합니다. 조합할 수 있는 방법은 다음과 같습니다.
- Repetitions(반복) : 트리거를 반복적으로 수행합니다. 정기적이고 주기적인 업데이트를 제공하기 위해서 처리시간 트리거와 함께 사용합니다.
- Conjunctions(AND) : AND 조건으로 두개의 트리거 조건이 모두 만족해야 트리거가 됩니다. 예를 들어 Processing time trigger가 1분이고, Element count trigger가 100개이면, 윈도우가 시작된 후 1분 후에, Element count가 100개가 되면 트리거가 됩니다. 즉, 2가지 조건에 부합해야 합니다.
- Disjunctions(OR) : OR 조건으로 두 트리거 중에 하나만 만족하면 트리거 됩니다.
- Sequence : Sequence는 정의된 트리거를 순차적으로 실행합니다. 즉, 첫 번째 트리거를 1분짜리 Processing time trigger를 등록하고 두 번째는 Element count가 100개인 트리거를 등록한 경우에, 윈도우 시작 후 1분 후에 트리거가 되고, 그 후에는 Element가 100개가 들어오면 두 번재 트리거가 된 후에 종료되는 방식입니다.
Allowed Lateness
늦은 데이터가 도착했을 때 데이터를 적절하게 처리할 수 있도록 허용되는 시간동안 윈도우의 지속상태를 지속해야 합니다. 사실 지연된 데이터를 처리하기 위해서 상태를 계속 유지할 수 있으면 좋겠지만 스트림 처리에서는 제한된 리소스로 인해 불가능합니다. 결과적으로 윈도우의 생명주기를 제한하는 방법을 제공해야 하고 허용되는 지연 시간에 관한 정보가 즉, 워터마크가 윈도우의 끝나는 지점에서부터 지연시간을 초과하는 것을 기준으로 설정됩니다. 그리고 이 이후에 들어온 모든 데이터는 드랍하게 됩니다.
Accumulation
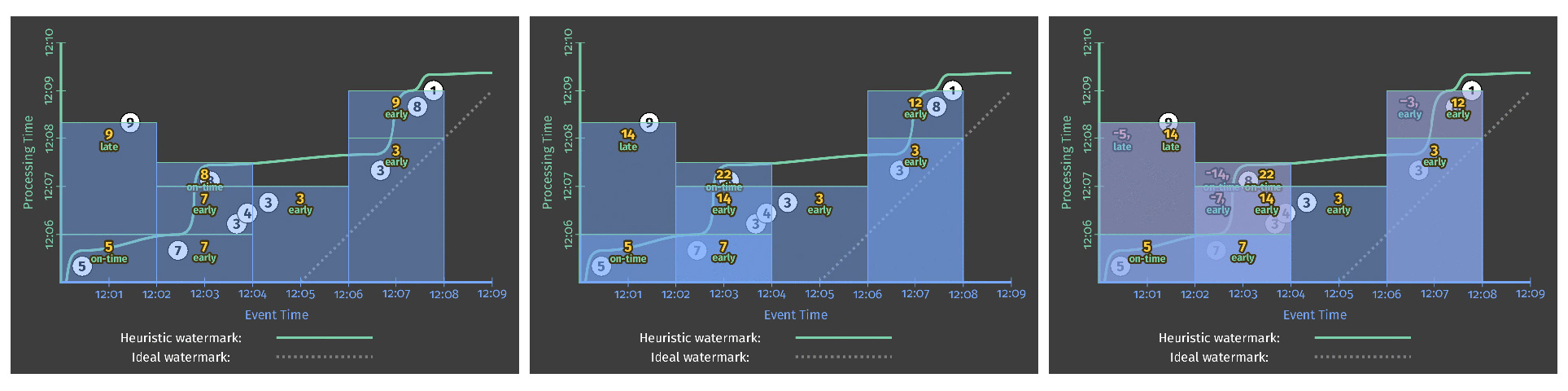
트리거 이후 결과를 어떻게 반영할 것인지 결정해야 합니다. 윈도우의 결과는 3가지의 어큐뮬레이션 모드가 있습니다. 3가지의 종류는 다음과 같습니다.
- Discarding
각 윈도우 결과가 독립적입니다. 이전 윈도우의 결과는 다음의 윈도우 결과와 독립적입니다. - Accumulating
기존의 모든 상태가 유지되면서 윈도우의 결과가 누적되는 방식입니다. - Accumulating & retracting
누적 모드와 비슷하지만 이전에 누적된 결과를 철회하고 수정하는 방식입니다.
트리거의 결과를 반영하는 방식을 나타내는 그림이 다음과 같습니다.
정리
본 포스트를 통해 스트림 처리의 개념들을 익혔을 것이라고 생각됩니다. 스트림 처리의 개념을 이해하기 위해 4가지 질문에 관해 스트림 처리에선 어떻게 해결하는지 정리해보면 다음과 같습니다.
- 어떤 결과가 계산될까요? => 트랜스포메이션
- 이벤트 시간 중 어디에서 결과가 계산될까요? => 윈도우
- 처리 시간에서 언제 결과가 구체화될까요? => 워터마크와 트리거
- 어떻게 결과 여부를 반영시킬 수 있을까요? => 어큐뮬레이션 모드
References
- https://www.oreilly.com/radar/the-world-beyond-batch-streaming-102/#L1
- https://bcho.tistory.com/1124?category=633903